请注意,本文编写于 201 天前,最后修改于 201 天前,其中某些信息可能已经过时。
目录
在编程中,我们经常需要从字符串中提取部分内容。在处理多语言和多字符类型(如汉字、全角字符)字符串时,字符可能占用不同的字节长度。为了解决这个问题,本文将介绍如何在 C# 中从一个混合字符串中按字节计数准确提取子字符串。
应用场景
以下是一些需要按字节计算提取字符串的场景:
- 文本显示限制:为了保证界面上一行字符的排列整齐,可能需要根据显示区域的字节限制提取字符串。
- 文件格式解析:一些文件格式可能要求字段长度按字节计算,尤其是在多语言环境下。
- 数据库存储优化:在某些数据库中,需要根据字节长度截取字符串以确保数据不超长。
在处理这些问题时,我们需要考虑字符串中的字符是以几字节为单位,如汉字通常为2字节,而全角字符也通常以2字节表示。
代码实现
以下代码展示了如何在 C# 中编写一个方法,按字节长度从字符串中提取子字符串。
C#using System;
class Program
{
static void Main()
{
string input = "Hello,世界123";
int startIndex = 6; // 指定位置(以字节数为单位)
int length = 6; // 指定长度(以字节数为单位)
string result = SubstringByByteLength(input, startIndex, length);
Console.WriteLine(result); // 输出结果
}
static string SubstringByByteLength(string input, int startIndex, int length)
{
if (input == null || startIndex < 0 || length < 0)
throw new ArgumentException("Input parameters are invalid.");
int currentLength = 0;
int currentIndex = 0;
int startCharIndex = -1;
// 查找起始的字符索引
while (currentIndex < input.Length && currentLength < startIndex)
{
char c = input[currentIndex];
int charLength = IsDoubleByte(c) ? 2 : 1;
if (currentLength + charLength > startIndex)
break;
currentLength += charLength;
currentIndex++;
}
startCharIndex = currentIndex;
// 初始化子字符串
currentLength = 0;
currentIndex = startCharIndex;
while (currentIndex < input.Length && currentLength < length)
{
char c = input[currentIndex];
int charLength = IsDoubleByte(c) ? 2 : 1;
if (currentLength + charLength > length)
break;
currentLength += charLength;
currentIndex++;
}
// 提取子字符串范围
return input.Substring(startCharIndex, currentIndex - startCharIndex);
}
// 判断字符是否为汉字或全角字符
static bool IsDoubleByte(char c)
{
// Unicode 4E00-9FFF 是汉字
// 全角字符范围通常从FF00-FFEF
return (c >= 0x4E00 && c <= 0x9FFF) ||
(c >= 0xFF01 && c <= 0xFF60) ||
(c >= 0xFFE0 && c <= 0xFFE6);
}
}
详细示例
示例输入
假设我们有以下字符串:
text"Hello,世界123"
并希望从字节索引 6 开始,截取 6 个字节的内容。
计算过程
- 第一个字符 ****
H:占1字节,累计1字节。 - 第二个字符 ****
e:占1字节,累计2字节。 - 第三个字符 ****
l:占1字节,累计3字节。 - 第四个字符 ****
l:占1字节,累计4字节。 - 第五个字符 ****
o:占1字节,累计5字节。 - 第六个字符
,(全角逗号):占2字节,累计7字节(超过索引6,作为起始字符)。 - 第七个字符 ****
世:占2字节,开始累计到达8字节(条件不满足,不再包括此字符)。
最终输出
从第6个字节位置截取6个字节长度后,输出为:
text“,世”
一个具体实例
这样一个文本文件,需要读取信息
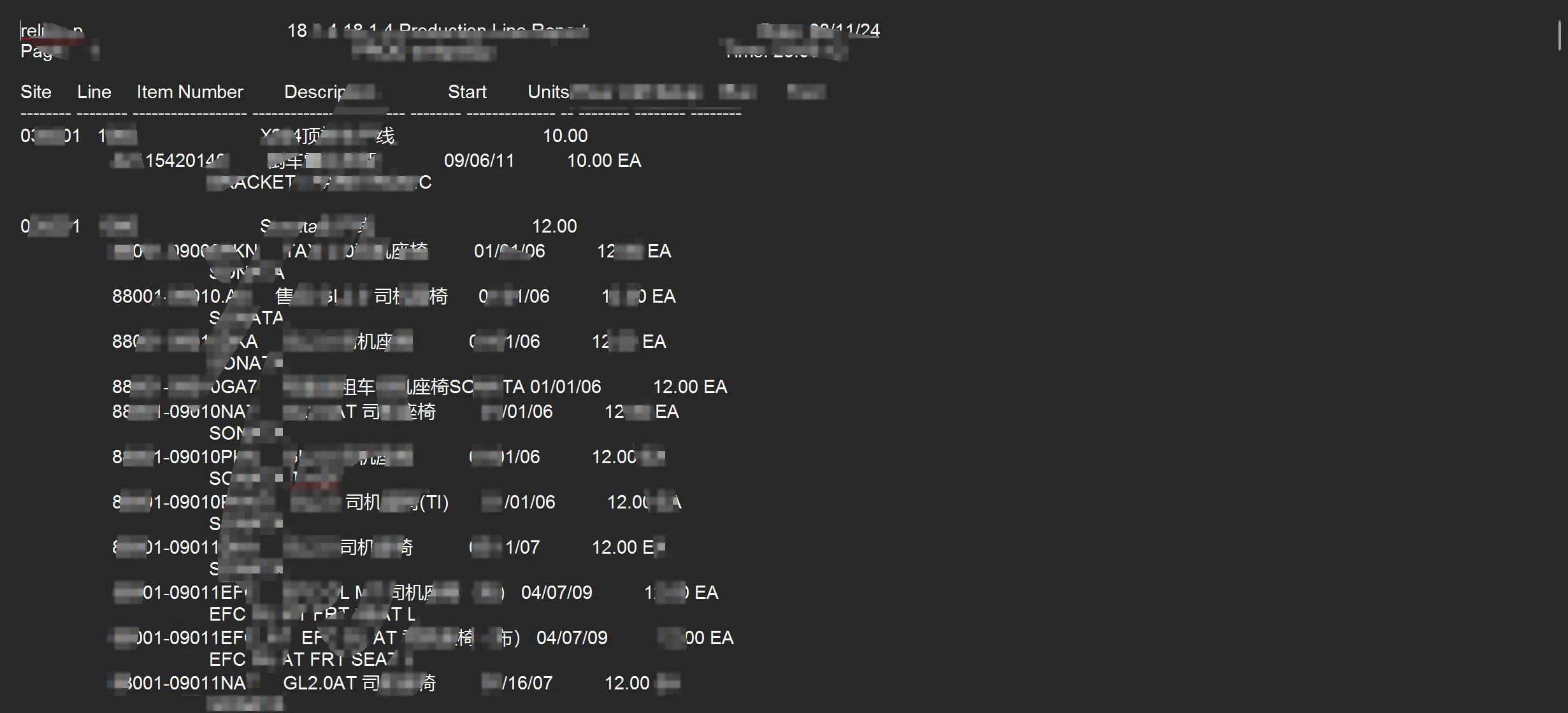
C#static void Main()
{
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
string file = "D:\\myproject\\1IdioSoft\\a\\files\\amfpc081124230016.txt";
string fileContext = File.ReadAllText(file, Encoding.GetEncoding("GB2312"));
List<string> rows = fileContext.Split('\n').Where(x => x.Trim() != "" && !x.Contains("Site")
&& !x.Contains("Batch")
&& !x.Contains("Item Number")
&& !x.Contains("--------------------")
&& !x.Contains("18.1.4")
&& !x.Contains("relnrp")
&& !x.Contains("Report Criteria")
&& !x.Contains("Production Line")
&& !x.Contains("Start")
&& !x.Contains("Report Criteria")
&& !x.Contains("Output: webpage")
&& !x.Contains("relnrp.p")
&& !x.Contains("Page:")
).ToList();
string site = "";
string line = "";
List<dynamic> pos = new List<dynamic>();
foreach (var row in rows)
{
string t_site = SubstringByByteLength(row, 0, 8).Trim();
if (t_site == "")
{
t_site = site;
}
else
{
site = t_site;
}
string t_line = SubstringByByteLength(row, 9, 8).Trim();
if (t_line == "")
{
t_line = line;
}
else
{
line = t_line;
}
string part_no = SubstringByByteLength(row, 18, 18).Trim();
if (part_no == "")
{
continue;
}
string description = SubstringByByteLength(row, 37, 24).Trim();
pos.Add(new
{
site = site,
line = line,
part_no = part_no,
description = description
});
}
var d = pos;
}
总结
这段代码展示了在 C# 中处理具有变长字符宽度的字符串(特别是包括汉字和全角字符)的方法。通过按字节计算字符的长度,我们可以准确地提取所需的子字符串,即使在多语言或复杂字符集的情况下。这对处理国际化应用非常有用。
本文作者:rick
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录