目录
数据库设计是构建有效、高效和可维护数据库系统的关键步骤。在关系数据库理论中,设计过程遵循一系列原则和规范,以确保数据的一致性、完整性和可访问性。本文将详细介绍关系数据库的基本概念、设计过程、规范化理论,以及实体-关系模型。
关系数据库的基本概念
关系数据库由一系列相互关联的表格组成,每个表格代表数据中的一个实体类型。表格由行和列构成,行代表记录(实体的实例),列代表属性(实体的特征)。
表(Relation)
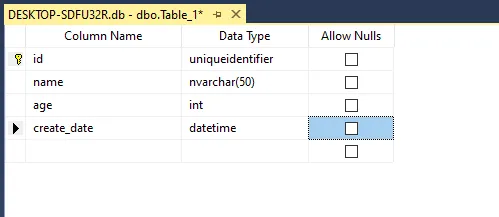
在关系数据库中,表是存储数据的主要结构。每个表都有一个唯一的名字,并且包含一系列具有特定数据类型的列。
列(Attribute)
列定义了表中存储的数据类型。每个列都有一个名字,比如“姓名”或“地址”,并且指定了数据类型,如字符串、整数或日期。
行(Tuple)
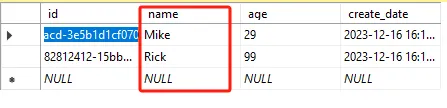
表中的每一行代表一个数据记录,是一组相关的数据项的集合。
主键(Primary Key)
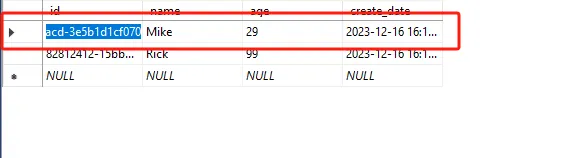
主键是表中的一个列(或一组列),用于唯一标识表中的每一行。没有两行可以有相同的主键值。
外键(Foreign Key)
外键是表中的一个列(或一组列),它引用另一个表的主键,用于建立两个表之间的关系。
数据库设计过程
数据库设计通常遵循以下步骤:
- 需求分析:确定数据库需要支持的业务需求。
- 概念设计:创建实体-关系模型(ER模型),定义实体、属性和它们之间的关系。
- 逻辑设计:将ER模型转换为关系模型,定义表、列和键。
- 物理设计:考虑数据库的物理存储和访问方法,创建索引和存储结构。
- 实现:使用数据库管理系统(DBMS)创建数据库、表和其他结构。
- 测试和评估:验证数据库是否满足需求,并进行性能评估。
规范化理论
规范化是数据库设计中用于减少数据冗余和提高数据完整性的过程。它通过一系列规范化形式(Normal Forms,NF)来实现。
第一范式(1NF)
确保每个表的每一列都是不可分割的基本数据项,每个表都有主键。
第一范式(1NF)是数据库规范化的最基本要求。它确保表中的每个字段都是原子的,也就是说,每个字段都不能再分解成更小的部分。此外,1NF要求表中的每一列都是唯一的,并且每行都有唯一的标识符,通常是主键。
下面是一个遵循第一范式(1NF)的表格示例:
假设我们有一个学生课程成绩表 StudentGrades,它记录了学生的成绩信息。
MarkdownStudentGrades
+------------+----------+---------+--------+
| Student_ID | FullName | Course | Grade |
+------------+----------+---------+--------+
| 1 | John Doe | Math | 85 |
| 1 | John Doe | Science | 90 |
| 2 | Jane Doe | Math | 92 |
| 2 | Jane Doe | History | 88 |
| 3 | Jim Ray | Math | 75 |
| 3 | Jim Ray | Science | 80 |
+------------+----------+---------+--------+
在这个例子中,StudentGrades 表遵循了第一范式的规则:
- 每个字段值都是原子的,没有任何字段可以再分解成更小的部分。例如,
FullName字段包含完整的名字,没有将名和姓分开存储。 - 表中的每一列都是唯一的,没有两列是相同的信息。
- 表中的每一行都可以通过
Student_ID和Course的组合来唯一识别,这个组合可以作为复合主键。虽然Student_ID本身并不唯一,但与Course字段的组合确保了每一行都是唯一的。
遵循第一范式是数据库设计的基础,它有助于保证数据的完整性和减少数据冗余。
第二范式(2NF)
在1NF的基础上,确保表中的所有非主键列都完全依赖于主键。
第二范式(2NF)是在第一范式(1NF)的基础上进一步规范化的结果。2NF 要求数据库表不仅要满足 1NF 的要求,而且还要确保所有非主键字段完全依赖于主键。如果主键是由多个字段组成的复合主键,则所有非主键字段都必须依赖于整个复合主键,而不是仅依赖于复合主键的一部分。
以下是一个例子,展示了从不符合 2NF 的表格转变为符合 2NF 的表格的过程。
假设我们有一个不符合 2NF 的学生课程成绩表 StudentCourses,它记录了学生的课程成绩以及授课老师的信息。
MarkdownStudentCourses (不符合 2NF)
+------------+----------+---------+--------+-----------+
| Student_ID | FullName | Course | Grade | Instructor|
+------------+----------+---------+--------+-----------+
| 1 | John Doe | Math | 85 | Mr. Smith |
| 1 | John Doe | Science | 90 | Ms. Jones |
| 2 | Jane Doe | Math | 92 | Mr. Smith |
| 2 | Jane Doe | History | 88 | Mr. Brown |
| 3 | Jim Ray | Math | 75 | Mr. Smith |
| 3 | Jim Ray | Science | 80 | Ms. Jones |
+------------+----------+---------+--------+-----------+
在这个表中,Student_ID 和 Course 可以组成复合主键。但是,FullName 和 Instructor 字段只依赖于 Student_ID 或 Course 的一部分,而不是整个复合主键。为了符合 2NF,我们需要消除部分依赖,将数据分解成两个表格。
我们可以创建两个表格:一个是学生表 Students,另一个是课程成绩表 CourseGrades。
MarkdownStudents (符合 2NF)
+------------+----------+
| Student_ID | FullName |
+------------+----------+
| 1 | John Doe |
| 2 | Jane Doe |
| 3 | Jim Ray |
+------------+----------+
CourseGrades (符合 2NF)
+------------+---------+--------+-----------+
| Student_ID | Course | Grade | Instructor|
+------------+---------+--------+-----------+
| 1 | Math | 85 | Mr. Smith |
| 1 | Science | 90 | Ms. Jones |
| 2 | Math | 92 | Mr. Smith |
| 2 | History | 88 | Mr. Brown |
| 3 | Math | 75 | Mr. Smith |
| 3 | Science | 80 | Ms. Jones |
+------------+---------+--------+-----------+
在这两个表中,Students 表只包含学生的唯一信息,Student_ID 作为主键。CourseGrades 表包含了课程成绩和授课老师的信息,其中 Student_ID 和 Course 的组合作为复合主键,确保了每个学生的每门课程成绩都是唯一的。这样,每个非主键字段(Grade 和 Instructor)都完全依赖于复合主键(Student_ID + Course),满足了 2NF 的要求。
第三范式(3NF)
在2NF的基础上,确保表中的所有非主键列都只依赖于主键,而不依赖于其他非主键列。
第三范式(3NF)要求一个数据库表不仅要满足第二范式(2NF),而且还要确保所有非主键字段之间没有传递依赖(即每个非主键字段只依赖于主键,不依赖于其他非主键字段)。
以下是一个例子,展示了从不符合 3NF 的表格转变为符合 3NF 的表格的过程。
假设我们有一个不符合 3NF 的订单表 Orders,它记录了订单信息以及客户的信息。
MarkdownOrders (不符合 3NF)
+-----------+------------+-----------------+-----------+-----------------+--------------+
| Order_ID | Product_ID | Product_Name | Quantity | Customer_ID | Customer_Name|
+-----------+------------+-----------------+-----------+-----------------+--------------+
| 1001 | 500 | Widget A | 10 | C001 | Alice Smith |
| 1002 | 501 | Widget B | 5 | C002 | Bob Jones |
| 1003 | 500 | Widget A | 2 | C003 | Carol Lee |
| 1004 | 502 | Widget C | 3 | C001 | Alice Smith |
| 1005 | 501 | Widget B | 1 | C002 | Bob Jones |
+-----------+------------+-----------------+-----------+-----------------+--------------+
在这个表中,Order_ID 作为主键,但我们可以看到,Product_Name 依赖于 Product_ID,而 Customer_Name 依赖于 Customer_ID。这些依赖关系都是传递依赖,因为这些字段依赖于非主键字段。为了符合 3NF,我们需要消除传递依赖,将数据分解成三个表格。
我们可以创建三个表格:一个是订单表 Orders,一个是产品表 Products,还有一个是客户表 Customers。
MarkdownOrders (符合 3NF)
+-----------+------------+-----------+-----------------+
| Order_ID | Product_ID | Quantity | Customer_ID |
+-----------+------------+-----------+-----------------+
| 1001 | 500 | 10 | C001 |
| 1002 | 501 | 5 | C002 |
| 1003 | 500 | 2 | C003 |
| 1004 | 502 | 3 | C001 |
| 1005 | 501 | 1 | C002 |
+-----------+------------+-----------+-----------------+
Products (符合 3NF)
+------------+-----------------+
| Product_ID | Product_Name |
+------------+-----------------+
| 500 | Widget A |
| 501 | Widget B |
| 502 | Widget C |
+------------+-----------------+
Customers (符合 3NF)
+-----------------+--------------+
| Customer_ID | Customer_Name|
+-----------------+--------------+
| C001 | Alice Smith |
| C002 | Bob Jones |
| C003 | Carol Lee |
+-----------------+--------------+
在这些表中,Orders 表只包含订单的基本信息,其中 Order_ID 是主键。Products 表包含产品信息,Product_ID 是主键。Customers 表包含客户信息,Customer_ID 是主键。现在,每个非主键字段都只依赖于它们各自的主键,没有非主键字段之间的传递依赖,满足了 3NF 的要求。
BCNF(Boyce-Codd Normal Form)
是3NF的扩展,处理更复杂的依赖关系,确保每个非平凡的函数依赖都是对候选键的依赖。
BCNF(Boyce-Codd Normal Form)是数据库范式理论中的一种范式,它是对第三范式(3NF)的进一步加强。BCNF 是由数据库理论家 Raymond F. Boyce 和 Edgar F. Codd 提出的,因此得名。BCNF 解决了一些特殊情况,这些情况在 3NF 下仍然可能导致数据冗余。
BCNF 的定义是:一个关系模式 R 属于 BCNF,如果它属于 3NF,且对于它的每一个非平凡函数依赖 X -> A(其中 X 是 R 中的属性集,A 是 R 中的一个属性),X 都包含了 R 的一个候选键(即 X 是超键)。
简单来说,BCNF 要求:
- 表必须已经在 3NF 中。
- 表中的每个决定因素必须是候选键的一部分。
在 3NF 中,非主属性必须依赖于候选键,但是允许候选键之间相互依赖。而在 BCNF 中,即使是候选键也不能相互依赖,这意味着任何属性集(包括候选键)不能依赖于其他候选键的一部分。
BCNF 范式的主要目的是处理那些在 3NF 中仍然存在的数据冗余问题。BCNF 比 3NF 更加严格,但也更难以达到,因为在某些情况下,为了满足 BCNF,可能需要进行大量的分解,这可能会导致查询效率的下降。
举个简单的例子,假设有一个课程表 CourseInstructors,其中包括 CourseID(课程ID)、InstructorID(讲师ID)和 CourseName(课程名称)。
MarkdownCourseInstructors +-----------+--------------+-------------+ | CourseID | InstructorID | CourseName | +-----------+--------------+-------------+ | CSCI101 | I23 | Programming | | MATH222 | I27 | Algebra | | CSCI101 | I24 | Programming | +-----------+--------------+-------------+
在这个例子中,CourseID 决定了 CourseName,但是 CourseID 和 InstructorID 一起才能唯一确定一条记录。在这种情况下,CourseID 是一个候选键的一部分,但它也是 CourseName 的决定因素,这违反了 BCNF。为了满足 BCNF,我们可以将表分解为两个表:
MarkdownCourses +-----------+-------------+ | CourseID | CourseName | +-----------+-------------+ | CSCI101 | Programming | | MATH222 | Algebra | +-----------+-------------+ TeachingAssignments +-----------+--------------+ | CourseID | InstructorID | +-----------+--------------+ | CSCI101 | I23 | | MATH222 | I27 | | CSCI101 | I24 | +-----------+--------------+
现在,每个表都满足 BCNF,因为它们的每个属性都只依赖于候选键。
实体-关系模型(ER模型)
实体-关系模型是一种高级概念模型,用于在逻辑设计阶段之前描述数据的概念结构。ER模型包括:
- 实体:现实世界中可以区分的对象或事物。
- 属性:描述实体特征的数据项。
- 关系:实体之间的逻辑联系。
- ER图:图形化表示ER模型的图表。
结论
关系数据库理论是数据库设计和管理的基石。通过理解和应用关系模型、规范化理论和ER模型,设计者可以创建出结构良好、高效和可维护的数据库系统。良好的数据库设计对于确保数据的质量和系统的性能至关重要。随着技术的发展,虽然出现了新的数据库模型和设计方法,但关系数据库理论仍然是现代数据库设计的核心。
本文作者:rick
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!