你是否遇到过这样的开发场景:需要在某个应用程序关闭后自动执行清理操作?或者开发自动化测试工具时,需要等待被测应用退出后生成测试报告?又或者在开发插件管理器时,需要在主程序关闭后清理临时文件?
这些看似复杂的需求,其实都指向一个核心问题:如何在C#中准确检测其他应用程序是否已经关闭。本文将为你提供6种实战级解决方案,从基础到高级,让你轻松应对各种监控场景。
🎯 核心问题分析
在实际开发中,我们经常需要监控其他应用程序的状态,主要痛点包括:
- 时效性要求:需要第一时间感知应用关闭事件
- 资源消耗:频繁轮询会造成性能开销
- 权限限制:某些监控方法需要特殊权限
- 多实例处理:同名应用的多个实例如何区分
针对这些问题,我们需要根据不同场景选择合适的监控策略。
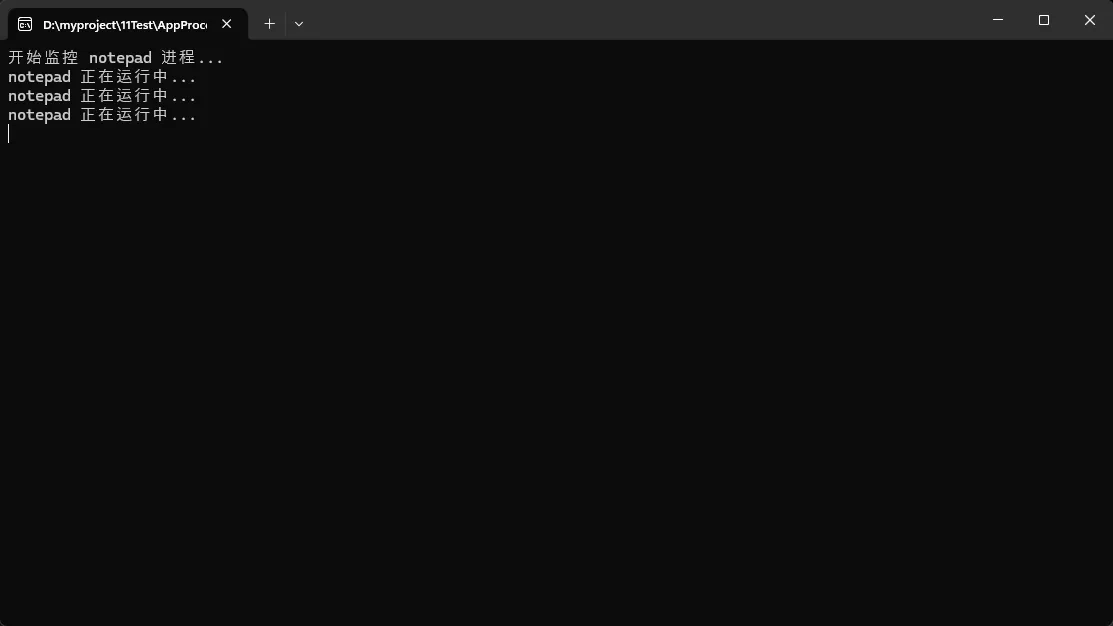
🚀 方法一:Process类基础监控(推荐新手)
最直接的方法是使用.NET内置的System.Diagnostics.Process类:
C#using System.Diagnostics;
namespace AppProcessMonitor
{
internal class Program
{
static void Main(string[] args)
{
// 要监控的应用程序名称(不含.exe扩展名)
string processName = "notepad";
Console.WriteLine($"开始监控 {processName} 进程...");
// 首先检查进程是否正在运行
if (!IsProcessRunning(processName))
{
Console.WriteLine($"{processName} 进程未运行!");
return;
}
// 持续监控进程状态直到关闭
while (IsProcessRunning(processName))
{
Console.WriteLine($"{processName} 正在运行中...");
Thread.Sleep(1000); // 每秒检查一次
}
Console.WriteLine($"🎉 {processName} 已关闭!");
// 在这里执行应用关闭后的操作
}
/// <summary>
/// 检查指定名称的进程是否正在运行
/// </summary>
static bool IsProcessRunning(string processName)
{
Process[] processes = Process.GetProcessesByName(processName);
return processes.Length > 0;
}
}
}
前一篇文章介绍MasterMemory,这个组件讨论的网友挺多了,有网友单独问我,说想用这个替换sqlite,我肯定是不支持的,虽然官方对比sqlite的性能与存储提示不少,但绝对不是db的读取逻辑。所以有了这篇文章,按网友说他现在30w数据在sqlite中大该150M,我模拟写了以下程序,试了一下,30万条设备数据,复杂的多维度筛选,用户输入关键词的瞬间就能看到结果。至于大家用在什么场景还是自己拿主义了。
作为C#开发者,你是否遇到过这些痛点:
- 数据库查询慢如蜗牛,用户体验糟糕
- 复杂的索引设计让人头疼
- 高并发下数据库压力山大
MasterMemory 优点
🚀 性能优势
- 毫秒级查询响应:30万数据查询速度<1ms,比传统数据库快200-500倍
- 零序列化开销:直接操作C#对象,无需序列化/反序列化过程,这个优势还是明显的。
- 预构建索引:启动时一次性构建所有索引,查询时直接使用
- 内存查询:避免磁盘I/O瓶颈,全内存操作
- 基本是source code 预编译的,这个可以看我以住的这个系列,算是写的比较清楚了。
💻 开发优势
- 类型安全:编译时检查,运行时高效,避免SQL语句错误。
- 强类型支持:原生C#对象操作,智能提示完整
- 复合索引支持:支持多字段联合索引,优化复杂查询
- 线程安全:只读特性天然保证线程安全
🔧 技术优势
- 支持复杂查询:范围查询、多条件筛选、模糊搜索等
- 高并发友好:避免数据库连接池压力
- 序列化持久化:支持二进制序列化保存到磁盘
MasterMemory 缺点
📝 功能限制
- 只读特性:数据更新需要重建整个数据库实例,不支持实时增删改,你想用这个替换db需要考虑的东西就多了,要是有时间我可以试试扩展一下它的写。
- 内存占用:30万数据约占用50-100MB内存,大数据集内存压力大
- 数据一致性:更新时需要全量重建,存在数据一致性时间窗口
🔧 技术限制
- 学习成本:需要掌握MessagePack序列化、索引设计等概念
- 过多索引开销:索引数量过多会增加内存占用和构建时间
- 依赖管理:需要额外引入MessagePack等第三方包
💾 存储限制
- 内存依赖:所有数据必须能装入内存
- 持久化复杂:数据持久化需要额外的序列化/反序列化逻辑
- 版本管理:数据结构变更时需要考虑兼容性问题
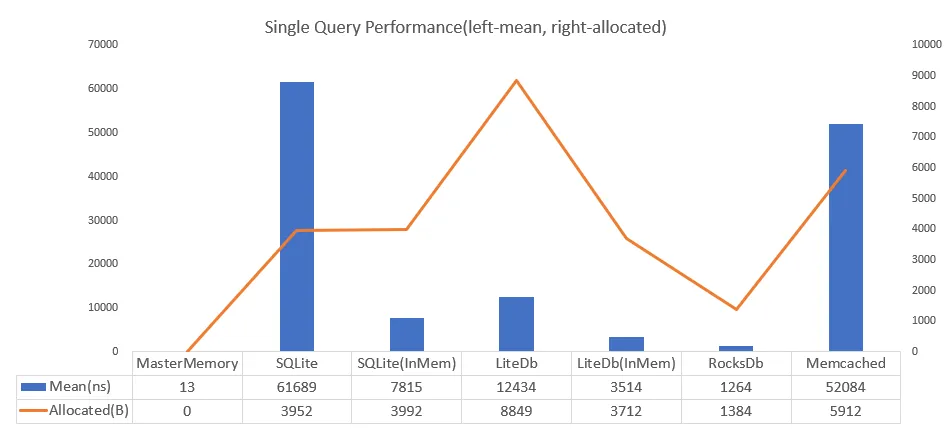
官方性能对比图
作为一名C#开发者,你是否在项目中遇到过这样的痛点:需要频繁查询配置数据、游戏数据或者静态资源数据,但传统数据库的性能瓶颈让应用卡顿不已?今天要为大家介绍的MasterMemory,正是为解决这一问题而生的革命性方案。
这个由Cysharp团队开发的开源项目,不仅在性能上碾压传统方案(比SQLite快4700倍!有点吹牛逼),更在类型安全和易用性上做到了极致。本文将深入解析MasterMemory的核心特性,并提供实战代码示例,让你快速掌握这个强大的内存数据库工具。
🎯 传统数据库方案的三大痛点
💔 性能瓶颈严重
传统的SQLite在处理频繁查询时,每次查询都需要进行文件I/O操作,在高并发场景下性能急剧下降。特别是在游戏开发、配置管理等需要大量读取操作的场景中,这种性能损耗是致命的。
🔍 缺乏类型安全
使用传统数据库时,SQL查询是字符串形式,编译期无法检查错误,只有在运行时才能发现问题。这不仅增加了调试难度,也容易引入生产环境的bug。
📦 内存占用过高
传统方案往往需要额外的ORM层,加上数据库引擎本身的开销,内存占用居高不下。对于嵌入式应用或移动端开发,这是个严重问题。
🛡️ MasterMemory:完美解决方案的五大优势
1. 🏃♂️ 极致性能表现
- 查询速度:比SQLite快4700倍
- 零内存分配:每次查询实现零GC压力
- 文件大小:相同数据量下,比SQLite小94%(SQLite 3560KB vs MasterMemory 222KB)
2. 🔒 100%类型安全
通过Source Generator技术,在编译期自动生成强类型API,彻底告别字符串拼接的查询方式。
3. 💾 内存高效利用
- 自动字符串驻留(String Interning)
- 只存储实际数据,无额外开销
- 支持并行构建优化
4. 🎮 跨平台支持
完美支持.NET和Unity,满足桌面应用、移动应用、游戏开发等多种场景需求。
5. 🔧 灵活查询能力
支持主键查询、多键组合查询、范围查询、最近值查询等多种查询方式。
你还在为批量处理大量图片而头疼吗?设计师需要将几百张产品图片统一缩放,运营同学要批量压缩社交媒体素材,开发者要为移动端适配不同尺寸的图标...
今天,我将分享一个完整的C#批量图片处理解决方案,让你1分钟处理1000张图片,彻底告别重复劳动!
🎯 痛点分析:为什么需要批量图片处理?
在实际开发中,我们经常遇到这些场景:
- 电商系统:产品图片需要生成多种尺寸的缩略图
- 移动应用:图标适配不同分辨率的设备
- 网站优化:批量压缩图片提升加载速度
- 内容管理:统一调整图片尺寸和格式
手动处理这些任务不仅效率低下,还容易出错。今天我们就用C#打造一个专业级的批量处理工具!
💡 解决方案:基于SkiaSharp的高性能图片处理
🔧 技术选型
我们选择SkiaSharp作为图片处理库,原因如下:
- 跨平台支持:Windows、Linux、macOS全覆盖
- 高性能:基于Google Skia引擎,GPU加速
- 功能丰富:支持多种图片格式和高质量缩放算法
- 内存优化:自动管理内存,避免内存泄漏
身为C#开发者,你是否遇到过这样的困扰?
用户误删重要数据,没有任何提醒;程序出错了,用户完全不知道发生了什么;想让用户确认某个操作,却不知道如何优雅地实现...
这些问题的根源都指向同一个核心:缺少有效的用户交互机制。在WinForms开发中,MessageBox作为最基础的交互工具,看似简单却蕴含着巨大的潜力。
今天我将分享5个MessageBox的实战技巧,帮你彻底掌握这个"看起来简单,用起来复杂"的组件,让你的应用程序用户体验瞬间提升一个档次!
🎯 痛点分析:为什么你的MessageBox总是"不给力"?
很多开发者对MessageBox的认知还停留在简单的 MessageBox.Show("Hello World") 层面,导致:
- 用户体验差:缺少必要的视觉反馈
- 逻辑处理不当:没有正确处理用户的选择结果
- 界面不够专业:消息提示千篇一律,缺少针对性
💡 5个实战解决方案
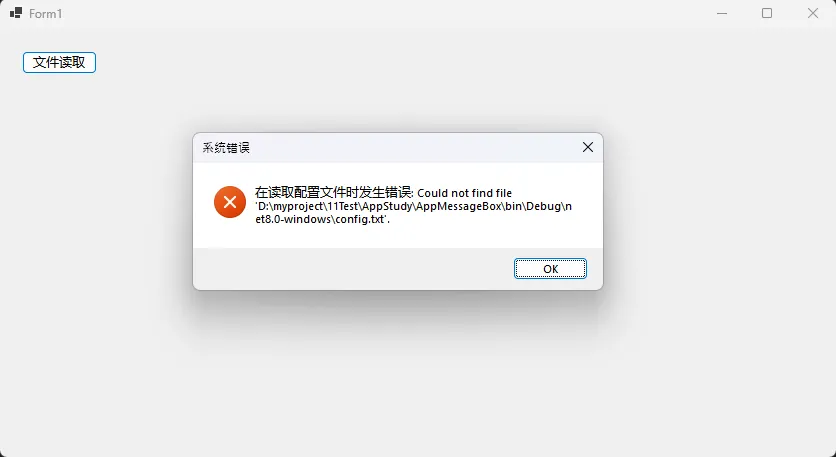
🚀 技巧1:智能化错误提示系统
应用场景:文件操作、数据库连接、网络请求等可能出错的操作
C#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace AppMessageBox
{
public static class ErrorHandler
{
public static void ShowError(Exception ex, string context = "")
{
string errorMessage = string.IsNullOrEmpty(context)
? $"发生错误: {ex.Message}"
: $"在{context}时发生错误: {ex.Message}";
MessageBox.Show(
errorMessage,
"系统错误",
MessageBoxButtons.OK,
MessageBoxIcon.Error,
MessageBoxDefaultButton.Button1
);
}
}
}
C#using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespace AppMessageBox
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void btnReadFile_Click(object sender, EventArgs e)
{
try
{
// 文件读取操作
string content = File.ReadAllText("config.txt");
}
catch (Exception ex)
{
ErrorHandler.ShowError(ex, "读取配置文件");
}
}
}
}