
你是否经常为写大量的样板代码而烦恼?创建一个简单的数据类,却要写几十行的构造函数、属性、Equals、GetHashCode等方法?或者担心内部工具类被外部误用,想要更精确的访问控制?
**今天我们来探索C#中两个强大却容易被忽视的特性:Record类型和File修饰符。**这两个特性能够显著减少样板代码,提升代码的可维护性和安全性。本文将通过完整的实战示例,带你掌握这两个现代C#开发的必备技能。
🔍 问题分析:传统代码的痛点
样板代码泛滥的困扰
在传统的C#开发中,我们经常遇到这些问题:
- 数据类冗长:一个简单的数据传输对象需要大量样板代码
- 值比较复杂:实现正确的相等性比较需要重写多个方法
- 不可变性难实现:创建不可变对象需要很多额外工作
- 访问控制粗糙:只有public、private等,缺乏文件级别的精确控制
C#// 传统方式:大量样板代码
public class TraditionalPerson
{
public string Name { get; }
public int Age { get; }
public string Email { get; }
public TraditionalPerson(string name, int age, string email)
{
Name = name;
Age = age;
Email = email;
}
public override bool Equals(object obj) { /* 复杂实现 */ }
public override int GetHashCode() { /* 复杂实现 */ }
public override string ToString() { /* 自定义实现 */ }
// ... 更多样板代码
}
作为一名.NET开发者,你是否还在为复杂的事件订阅管理而头疼?是否因为传统事件机制导致的内存泄漏而困扰?今天我要为你介绍一个革命性的解决方案——Easy.MessageHub,一个轻量级、高性能的消息传递框架,让你彻底摆脱传统事件的束缚!
本文将通过一个完整的工业监控系统示例,带你深入了解如何用Easy.MessageHub构建优雅的消息驱动架构,解决传统事件机制的痛点。这个算是我看到最简单的事件总线三方库了,值得学习一下。
🚨 传统事件机制的三大痛点
1. 内存泄漏风险
C#// 传统事件容易忘记取消订阅
public class SensorService
{
public event EventHandler<TemperatureEventArgs> TemperatureChanged;
// 如果忘记取消订阅,就会内存泄漏!
}
2. 强耦合问题
发布者和订阅者之间必须有直接引用关系,违背了低耦合原则。
3. 生命周期管理复杂
需要手动管理事件的订阅和取消订阅,代码繁琐且容易出错。
💡 Easy.MessageHub:优雅的解决方案
Easy.MessageHub采用发布-订阅模式,提供了以下核心优势:
- ✅ 弱引用机制:自动防止内存泄漏
- ✅ 零依赖注入:发布者和订阅者完全解耦
- ✅ 线程安全:天然支持多线程环境
- ✅ 类型安全:强类型消息定义,编译时检查
🚩 流程
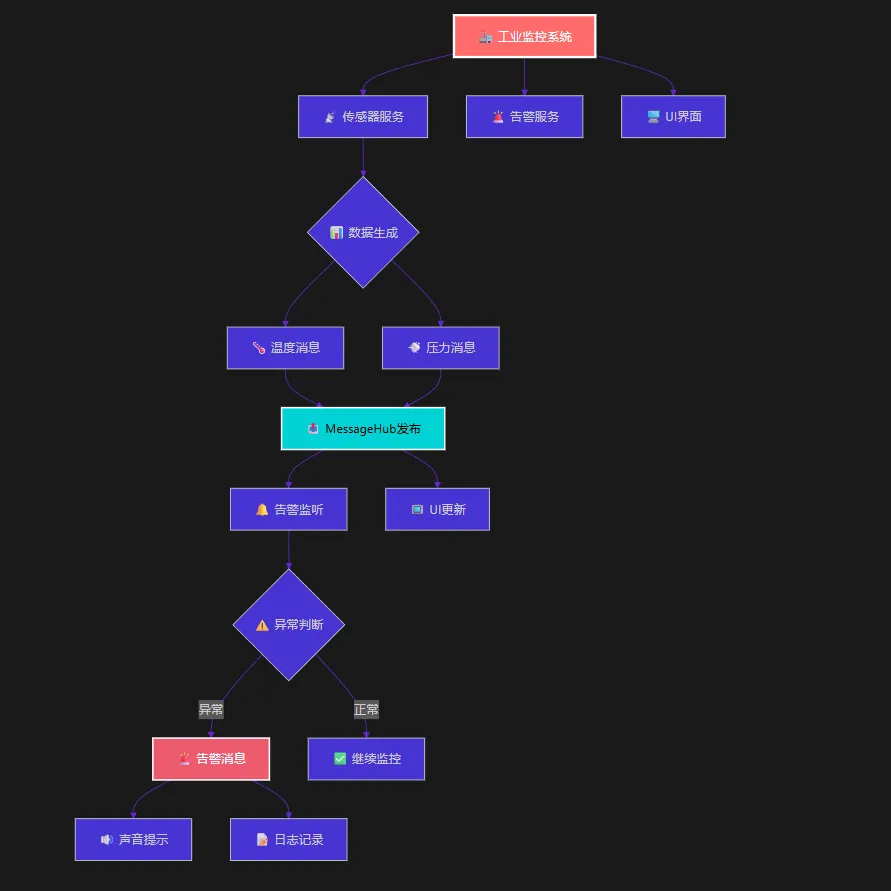
🛠️ 实战:构建工业监控系统
让我们通过一个完整的工业监控系统来展示Easy.MessageHub的强大功能。
📦 项目结构
C#AppMessageHub/
├── Messages/ # 消息定义
├── Services/ # 业务服务
├── Forms/ # UI界面
└── Program.cs # 入口文件
作为一名C#开发者,你是否遇到过这样的场景:需要批量处理文件、自动化测试桌面应用、或者让程序自动操作其他软件?手动操作既耗时又容易出错,而传统的API集成方案往往受限于第三方应用的开放性。
今天就来分享一个C#开发者的"秘密武器"——UI Automation。通过这个技术,你可以让程序像人一样操作任何Windows应用程序,实现真正的"所见即所得"自动化。本文将通过一个完整的记事本自动化实例,教你掌握这项实用技能。
🔍 痛点分析:为什么需要UI自动化?
在实际开发中,我们经常遇到这些困扰:
传统方案的局限性:
- API集成:依赖第三方应用提供接口,很多软件根本没有
- 脚本录制工具:功能单一,无法与C#项目深度集成
- 人工操作:效率低下,容易出错,无法批量处理
UI Automation的优势:
- 🎯 通用性强:支持所有Windows应用程序
- 🔧 原生集成:微软官方技术,与.NET完美兼容
- 💪 功能全面:查找控件、模拟点击、文本输入、状态检测
🛠️ 技术方案:UI Automation核心架构
UI Automation基于Windows的可访问性架构,每个UI元素都有对应的自动化对象,我们可以通过以下方式操作:
C#// 核心组件架构
IUIAutomation automation = new CUIAutomation(); // 自动化引擎
IUIAutomationElement desktop = automation.GetRootElement(); // 桌面根元素
IUIAutomationCondition condition; // 查找条件
IUIAutomationElement targetElement; // 目标控件
🚀 实战代码:记事本完整自动化方案
📦 项目配置
首先创建项目文件,添加必要的依赖:
XML<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net8.0</TargetFramework>
<UseWindowsForms>true</UseWindowsForms>
</PropertyGroup>
<ItemGroup>
<COMReference Include="UIAutomationClient">
<WrapperTool>tlbimp</WrapperTool>
<Guid>944de083-8fb8-45cf-bcb7-c477acb2f897</Guid>
</COMReference>
</ItemGroup>
</Project>
🤔 你是否遇到过这样的问题?
开发WinForms应用时,用户总是抱怨文件选择界面不够友好?保存文件时缺少必要的提醒?多文件选择功能实现起来很复杂?
今天,我们就来彻底解决这些让C#开发者头疼的文件操作问题!通过掌握OpenFileDialog和SaveFileDialog这两个强大的组件,让你的应用用户体验瞬间提升一个档次。
🎯 为什么文件操作对话框如此重要?
在Windows应用开发中,文件操作是最常见的需求之一。无论是打开配置文件、导入数据还是导出报告,标准化的文件选择界面不仅能提升用户体验,还能避免路径输入错误等常见问题。
OpenFileDialog和SaveFileDialog的三大优势:
- ✅ 封装了复杂的Windows API,使用简单
- ✅ 提供标准化的用户界面,用户上手快
- ✅ 内置文件过滤、多选等高级功能
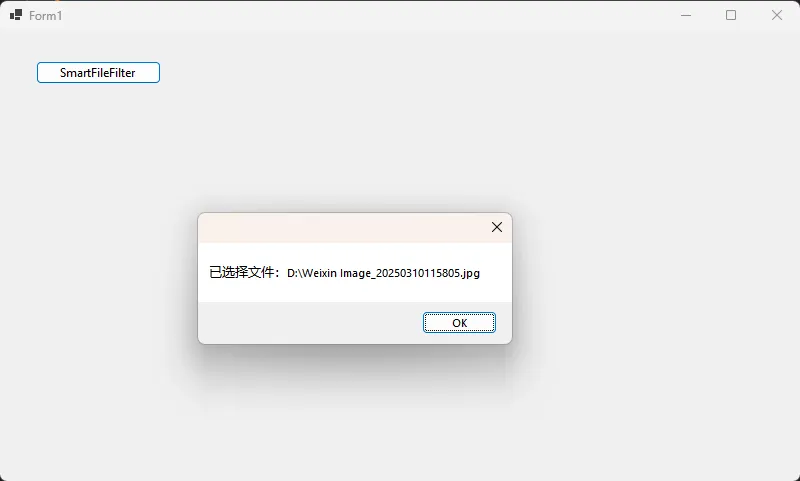
🔥 实战技巧一:智能文件过滤,提升用户体验
很多开发者只会设置基础的文件过滤,但合理的过滤设置能大大提升用户体验:
C#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace AppWinformFileDialog
{
public class SmartFileFilter
{
public void OpenWithSmartFilter()
{
using (OpenFileDialog openDialog = new OpenFileDialog())
{
// 关键技巧:设置多层次的文件过滤
openDialog.Filter = "图片文件 (*.jpg;*.png;*.gif)|*.jpg;*.png;*.gif|" +
"文档文件 (*.txt;*.doc;*.pdf)|*.txt;*.doc;*.pdf|" +
"所有文件 (*.*)|*.*";
// 默认选择第一个过滤器
openDialog.FilterIndex = 1;
// 设置友好的标题
openDialog.Title = "选择要处理的图片文件";
// 记住用户的选择目录
openDialog.RestoreDirectory = true;
if (openDialog.ShowDialog() == DialogResult.OK)
{
string selectedFile = openDialog.FileName;
MessageBox.Show($"已选择文件:{selectedFile}");
}
}
}
}
}
在现代移动应用开发中,SkiaSharp 作为跨平台2D图形库,为C#开发者提供了强大的图形绘制能力。其中,复合变换(Composite Transform) 是实现复杂图形效果的核心技术,掌握它能让你的应用界面更加生动和专业。
本文将深入讲解SkiaSharp中的复合变换技术,通过丰富的实例帮助你快速掌握这一重要技能。
什么是复合变换?
复合变换 是指将多个基础变换(平移、旋转、缩放、倾斜等)组合使用,创造出更复杂的视觉效果。在SkiaSharp中,这些变换通过矩阵运算实现,可以让图形元素产生丰富的动态效果。
基础变换类型
- 平移变换(Translation) - 移动图形位置
- 旋转变换(Rotation) - 围绕某点旋转图形
- 缩放变换(Scale) - 改变图形大小
- 倾斜变换(Skew) - 使图形产生倾斜效果
核心概念:变换矩阵
SkiaSharp使用 SKMatrix 来表示变换矩阵。理解矩阵的组合规则是掌握复合变换的关键:
C#// 变换矩阵的基本结构
// [ScaleX SkewX TransX]
// [SkewY ScaleY TransY]
// [Persp0 Persp1 Persp2]
实战案例详解
案例1:旋转缩放组合效果
这个例子展示如何创建一个既旋转又缩放的矩形:
C#using SkiaSharp;
using SkiaSharp.Views.Desktop;
namespace AppTransforms
{
public partial class Form1 : Form
{
private SKGLControl skControl;
public Form1()
{
InitializeComponent();
skControl = new SKGLControl();
skControl.Dock = DockStyle.Fill;
skControl.PaintSurface += SkControl_PaintSurface;
this.Controls.Add(skControl);
this.BackColor = System.Drawing.Color.Black;
}
private void SkControl_PaintSurface(object? sender, SKPaintGLSurfaceEventArgs e)
{
DrawRotateScaleComposite(e.Surface.Canvas, e.Info);
}
public void DrawRotateScaleComposite(SKCanvas canvas, SKImageInfo info)
{
// 清空画布背景
canvas.Clear(SKColors.White);
// 创建画笔
using (var paint = new SKPaint())
{
paint.Color = SKColors.Blue;
paint.Style = SKPaintStyle.Fill;
paint.IsAntialias = true; // 开启抗锯齿
// 保存当前画布状态
canvas.Save();
// 移动到画布中心
canvas.Translate(info.Width / 2, info.Height / 2);
// 先缩放再旋转(注意顺序很重要)
canvas.Scale(1.5f, 0.8f); // X轴放大1.5倍,Y轴缩小到0.8倍
canvas.RotateDegrees(45); // 顺时针旋转45度
// 绘制矩形(以原点为中心)
var rect = new SKRect(-100, -30, 100, 30);
canvas.DrawRect(rect, paint);
// 恢复画布状态
canvas.Restore();
}
}
}
}
