作为C#开发者,你是否遇到过这样的困扰:用户希望自定义界面字体和颜色,但自己写选择器太复杂?或者想要快速实现类似Office软件那样的字体颜色选择功能?
今天我们来深入探讨C# WinForms中的FontDialog和ColorDialog——两个能让你的应用程序瞬间变得专业的神器!本文将通过实战案例,教你如何优雅地实现用户界面定制功能。
🔍 问题分析:为什么需要标准对话框?
在WinForms开发中,用户界面定制是提升用户体验的关键。传统做法是自己写颜色选择器和字体选择器,但这样做有三个致命问题:
- 开发成本高:需要大量代码实现复杂的UI逻辑
- 用户体验差:界面不统一,用户需要重新学习操作
- 兼容性问题:难以处理各种字体和颜色的边界情况
而使用系统标准对话框,用户熟悉操作流程,开发效率也大大提升。
🎯 解决方案:掌握两大核心对话框
🔤 FontDialog:让文字更有个性
FontDialog是字体选择的完美解决方案,它不仅能选择字体,还能同时设置大小、样式和颜色。
核心属性速览
C#FontDialog fontDialog = new FontDialog();
fontDialog.ShowColor = true; // 显示颜色选择
fontDialog.FontMustExist = true; // 只允许选择存在的字体
fontDialog.AllowVectorFonts = true; // 允许矢量字体
fontDialog.MaxSize = 72; // 最大字号
fontDialog.MinSize = 8; // 最小字号
你是否在WPF开发中遇到过这样的困惑:为什么有些属性可以实现数据绑定,有些却不行?为什么自定义控件的属性无法触发界面更新?如果你正在为这些问题感到困扰,那么今天我们就来彻底搞懂WPF中最核心的概念之一——依赖属性。
依赖属性(Dependency Property)是WPF架构的基石,它不仅支持数据绑定、样式、动画等高级功能,更是构建现代化WPF应用不可或缺的技术。掌握了依赖属性,你就掌握了WPF开发的精髓。
🤔 为什么需要依赖属性?
在传统的.NET属性系统中,普通的CLR属性无法满足WPF的高级需求。让我们通过一个实际案例来理解这个问题:
C#// 传统CLR属性的局限性
public class Student
{
public string Name { get; set; }
public int Age { get; set; }
}
这样的普通属性存在以下问题:
- 无法自动通知变更:属性值改变时,UI不会自动更新
- 不支持数据绑定:无法与XAML中的控件建立双向绑定关系
- 缺乏验证机制:无法在属性赋值时进行有效性检查
- 无法参与样式系统:不能通过样式或触发器来改变属性值
💡 依赖属性的核心特性
依赖属性通过以下机制解决了传统属性的痛点:
🎯 特性一:属性值优先级系统
依赖属性建立了一套完整的值优先级体系:
- 动画值(最高优先级)
- 本地值(通过代码直接设置)
- 触发器值
- 样式值
- 继承值
- 默认值(最低优先级)
🎯 特性二:变更通知机制
自动实现INotifyPropertyChanged接口的功能,无需手动编写通知代码。
🎯 特性三:内存优化
只有在属性被实际使用时才分配内存空间,大大减少了内存占用。
🛠️ 实战案例:创建自定义依赖属性
让我们通过一个实际的用户控件来演示如何创建和使用依赖属性:
📋 案例场景:温度显示控件
假设我们要创建一个温度显示控件,能够根据温度值自动改变颜色,并支持数据绑定。
项目中需要实时监控设备状态,传统的Chart控件性能不够,WinForms又要求高颜值界面?本文教你用ScottPlot 5.0 + Lightning.NET构建一个完整的工业监控系统,1000个数据点丝滑滚动,再也不用担心界面卡顿!
🎯 为什么选择Lightning.NET?
- 嵌入式数据库,无需安装SQL Server
- LMDB引擎,读写性能极佳
- 零配置,打包即可部署
🎯 痛点分析:为什么选择ScottPlot 5.0?
传统方案的局限性
大多数C#开发者在做数据可视化时,会首选微软自带的Chart控件。但在工业监控场景下,这个"老古董"很快就暴露出致命问题:
- 性能瓶颈:超过500个数据点就开始卡顿
- 界面老土:2000年代的审美,客户直接说"太丑"
- 功能受限:缺乏实时滚动、动态缩放等现代化交互
ScottPlot 5.0的优势
ScottPlot作为.NET生态中的"后起之秀",在5.0版本中进行了架构重构:
- 🚀 高性能渲染:轻松处理万级数据点
- 🎨 现代化UI:开箱即用的专业外观
- 📊 丰富图表类型:从基础折线图到复杂热力图
- ⚡ 实时更新:专为动态数据设计的API
🔧 技术选型:构建完整解决方案
核心技术栈
C#// 项目依赖包
<PackageReference Include="ScottPlot.WinForms" Version="5.0.21" />
<PackageReference Include="Lightning.NET" Version="0.15.1" />
<PackageReference Include="System.Text.Json" Version="8.0.0" />
💻 代码实战:核心功能实现
🏗️ 数据模型设计
C#public class SensorData
{
public int EquipmentId { get; set; } // 设备ID
public long Timestamp { get; set; } // Unix时间戳
public double Temperature { get; set; } // 温度
public double Pressure { get; set; } // 压力
public double Vibration { get; set; } // 振动
public double Speed { get; set; } // 转速
public string Status { get; set; } // 设备状态
}
在现代Web开发中,你是否遇到过这样的困扰:网站上线后突然崩溃,用户投诉不断,但却不知道系统的真实承载能力? 作为开发者,我们经常听到产品经理问:"这个接口能同时处理多少用户请求?",而你却只能凭经验给出一个模糊的答案。
今天,我将分享如何用C#从零打造一个专业级网站压力测试工具,不仅能够精确模拟高并发场景,还能通过可视化图表直观展现系统性能数据。无需付费工具,无需复杂配置,只要掌握核心技术,你就能拥有媲美商业级的性能测试利器!
🎯 为什么要自己造轮子?
痛点分析
市面上的压力测试工具要么功能单一,要么价格昂贵。作为C#开发者,我们需要的是:
- 高度可定制化的测试参数
- 实时可视化的性能数据
- 轻量级且易于扩展的架构
- 完全免费的解决方案
🚀 核心技术架构解析
技术栈选择
- WinForms + ScottPlot 5.0+:专业图表
- HttpClient + 异步编程:高性能HTTP请求处理
- SemaphoreSlim:智能并发控制
- TableLayoutPanel:响应式布局
🚩 架构流程
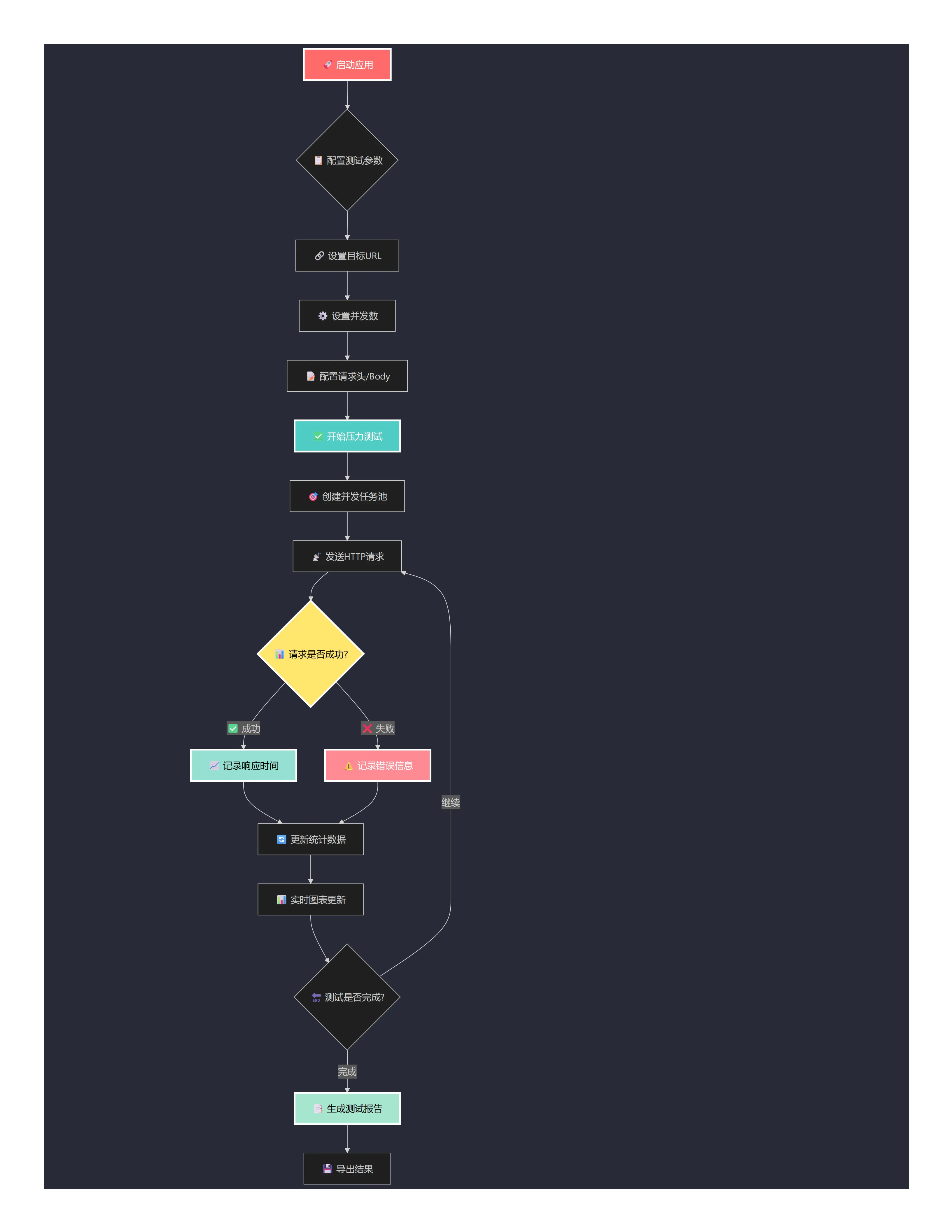
🔧 关键实现要点
1. 异步并发请求核心算法
C#private async Task ProcessRequestAsync(SemaphoreSlim semaphore, int requestId)
{
await semaphore.WaitAsync(cancellationTokenSource.Token);
try
{
var testResult = await SendHttpRequestAsync(requestId);
lock (lockObject)
{
testResults.Add(testResult);
completedRequests++;
if (testResult.IsSuccess)
{
successRequests++;
totalResponseTime += testResult.ResponseTime;
}
else
{
failedRequests++;
}
}
// 在UI线程中更新图表
if (InvokeRequired)
{
Invoke(new Action(() => UpdateChart(testResult)));
}
else
{
UpdateChart(testResult);
}
}
finally
{
semaphore.Release();
}
}
你是否曾经羡慕过那些酷炫的动态背景效果?想要在自己的C#应用中实现类似的视觉特效,却不知从何下手?
今天我将带你深入探索一个完整的波浪动画项目,涵盖圆形扩散波浪、水平流动波浪、螺旋旋转效果和粒子系统四种不同的视觉模式。这不仅仅是一个简单的Demo,而是一套可以直接应用到实际项目中的高性能动画解决方案。
无论你是想为企业应用添加动态元素,还是开发游戏界面,这篇文章都将为你提供完整的技术路径和实战代码。
🔍 技术痛点分析
传统GDI+的局限性
很多C#开发者在实现动画效果时,往往选择System.Drawing进行绘制。但传统方案存在明显短板:
- 性能瓶颈:复杂动画帧率低,用户体验差
- 功能受限:缺乏现代图形API的高级特性
- 跨平台困难:依赖Windows特有的GDI+
现代解决方案的必要性
随着应用对视觉效果要求越来越高,我们需要:
- 🚀 硬件加速的图形渲染
- 🎨 丰富多样的视觉效果
- ⚡ 流畅稳定的60FPS动画
- 🌐 跨平台兼容性
💡 SkiaSharp:现代C#图形编程的最佳选择
SkiaSharp是Google Skia图形库的.NET封装,为我们提供了强大的2D图形能力:
C#// 核心组件引入
using SkiaSharp;
using SkiaSharp.Views.Desktop;
// GPU加速控件
private SKGLControl skControl;
🔧 核心架构设计
我们的波浪动画系统采用模块化设计,通过状态模式实现四种不同效果:
C#public partial class Form5 : Form
{
private int waveMode = 0; // 波浪模式切换
private float currentTime = 0f; // 动画时间轴
private Timer animationTimer; // 60FPS定时器
// 四种波浪模式枚举
// 0=圆形波浪, 1=水平波浪, 2=螺旋波浪, 3=粒子波浪
}
🎨 四大波浪特效深度解析
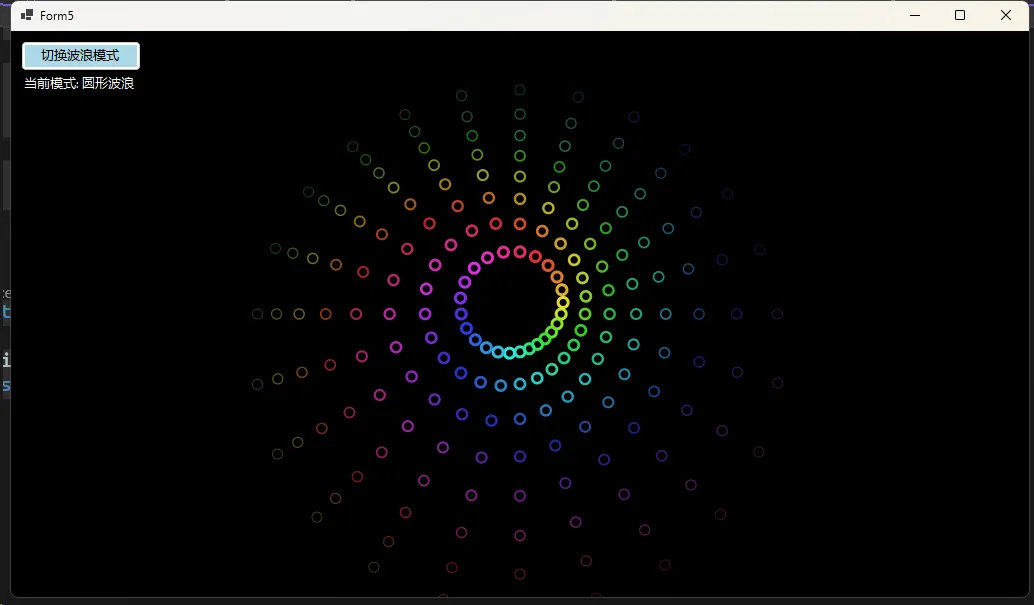
🌀 模式一:圆形扩散波浪
这种效果模拟了水滴落入水面产生的同心圆扩散,适用于加载界面或交互反馈:
C#private void DrawCircularWave(SKCanvas canvas, SKImageInfo info, float time)
{
canvas.Clear(SKColors.Black);
var centerX = info.Width / 2f;
var centerY = info.Height / 2f;
using (var paint = new SKPaint())
{
paint.IsAntialias = true;
paint.Style = SKPaintStyle.Stroke;
// 创建8层同心圆,每层包含24个波浪点
for (int ring = 0; ring < 8; ring++)
{
for (int i = 0; i < 360; i += 15)
{
// 关键算法:波浪相位计算
var wavePhase = (time + ring * 20 + i) * Math.PI / 180;
var baseRadius = 50 + ring * 30;
var waveAmplitude = 15 + ring * 3;
var radius = baseRadius + (float)(Math.Sin(wavePhase) * waveAmplitude);
// HSV颜色空间实现彩虹效果
var hue = (time * 2 + ring * 30 + i) % 360;
paint.Color = SKColor.FromHsv(hue, 80, 90).WithAlpha(alpha);
canvas.DrawCircle(x, y, 5, paint);
}
}
}
}