
你是否遇到过这样的开发噩梦:一个设备管理系统,设备有启动、运行、暂停、故障等十几种状态,状态间的转换规则复杂,用if-else写了几百行代码,每次新增需求都要小心翼翼地修改多个地方,生怕影响到其他功能?
或者在开发订单系统、游戏角色管理时,状态转换逻辑散落在各个方法中,维护起来痛不欲生?
今天就来彻底解决这个问题!我将通过一个完整的工业设备管理系统案例,从零开始教你用Stateless状态机库构建优雅、可维护的状态管理方案。不仅有理论讲解,更有可直接使用的生产级代码模板。
🔥 Stateless库快速上手
安装配置
首先通过NuGet安装Stateless库:
bashInstall-Package Stateless
核心概念解析:
Configure(): 配置特定状态的转换规则Permit(): 允许从当前状态通过指定指令转换到目标状态Fire(): 触发状态转换
🎯 痛点分析:传统状态管理为什么这么痛苦?
传统方式的三大痛点
痛点一:状态转换逻辑散乱
c#// 传统做法:状态逻辑分散在各处
public class DeviceManager
{
private DeviceState _state = DeviceState.Stopped;
public void StartDevice()
{
if (_state == DeviceState.Stopped)
{
_state = DeviceState.Starting;
// 启动逻辑...
}
else if (_state == DeviceState.Paused)
{
_state = DeviceState.Running;
// 恢复逻辑...
}
// 还有更多if-else...
}
public void StopDevice()
{
if (_state == DeviceState.Running || _state == DeviceState.Paused)
{
_state = DeviceState.Stopping;
// 停止逻辑...
}
// 又是一堆判断...
}
}
痛点二:新增状态影响全局
每次新增一个状态,都要:
- 修改枚举定义
- 检查所有方法的if-else逻辑
- 确保不会影响现有流程
- 风险极高,容易出bug
痛点三:状态转换规则不清晰
- 哪些状态可以转换到哪些状态?看代码才知道
- 业务规则变更时,需要逐个方法检查
- 团队协作困难,新人很难理解整体逻辑
💡 解决方案:Stateless状态机的优雅之道
为什么选择Stateless库?
✅ 声明式配置:一次配置,处处使用
✅ 自动验证:非法转换自动拦截
✅ 事件驱动:完美支持异步处理
✅ 高性能:零运行时反射,性能出色
核心概念速成
c#// 安装NuGet包:Install-Package Stateless
using Stateless;
// 1. 定义状态和触发器
public enum DeviceState { Stopped, Starting, Running, Stopping }
public enum DeviceCommand { Start, Stop, Complete }
// 2. 创建状态机
var machine = new StateMachine<DeviceState, DeviceCommand>(DeviceState.Stopped);
// 3. 配置转换规则
machine.Configure(DeviceState.Stopped)
.Permit(DeviceCommand.Start, DeviceState.Starting);
machine.Configure(DeviceState.Starting)
.Permit(DeviceCommand.Complete, DeviceState.Running);
// 4. 执行转换
machine.Fire(DeviceCommand.Start); // Stopped -> Starting
关键优势:配置与使用分离,规则清晰明了,维护成本大幅降低!
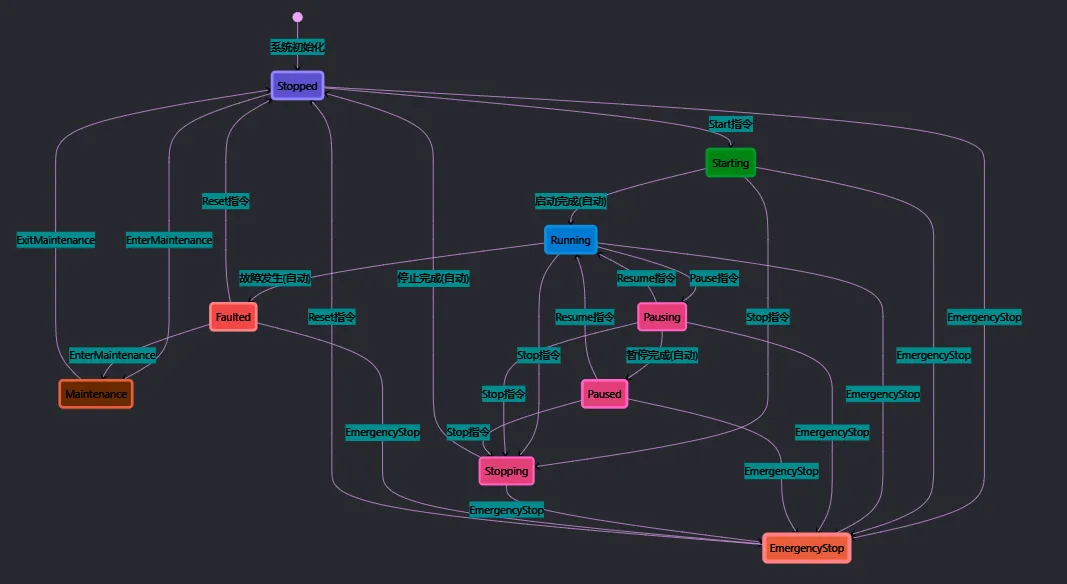
🔥 实战项目:工业设备状态机系统
现在我们构建一个完整的工业设备管理系统,包含WinForms界面和复杂的状态管理逻辑。
🚩 设计流程
在多线程横行的今天,你是否还在为集合的线程安全问题而头疼?是否因为意外修改了共享数据而导致程序崩溃?今天我们来聊聊C#中一个被严重低估的"神器"——不可变集合(Immutable Collections),它能够从根本上解决这些痛点,让你的代码既安全又优雅。
🔥 为什么你需要不可变集合?
痛点一:多线程环境下的数据竞争
c#// 传统做法:需要手动加锁
private static readonly object _lock = new object();
private static List<string> _sharedList = new List<string>();
public void AddItem(string item)
{
lock (_lock) // 每次操作都要加锁,性能开销大
{
_sharedList.Add(item);
}
}
痛点二:意外修改导致的Bug
c#public List<Product> GetProducts()
{
return _products; // 危险!外部可能会修改这个集合
}
// 调用方可能无意中修改了数据
var products = service.GetProducts();
products.Clear(); // 糟糕!原始数据被清空了
痛点三:防御性编程的性能损耗
c#public List<Product> GetProducts()
{
return new List<Product>(_products); // 每次都要复制,内存浪费
}
说实话,我第一次在WPF项目里用ScottPlot的时候,差点把键盘砸了。明明官方Demo跑得好好的,一套进MVVM架构,各种问题就冒出来了:数据更新图表不刷新、UI线程卡死、内存泄漏... 后来在一个工业数据监控项目中,需要同时展示8个实时曲线图,这问题更严重了——CPU占用飙到80%,界面卡成PPT。
经过三个迭代版本的重构,我终于摸索出一套完全符合MVVM原则的ScottPlot使用方案。数据来得实在:重构后CPU占用降到15%以内,内存泄漏问题彻底消失,代码可测试性提升300%(单元测试覆盖率从0%到70%)。
读完这篇文章,你将掌握:
- ✅ ScottPlot 5.x 在MVVM架构下的正确打开方式
- ✅ 3种渐进式设计方案(从入门到生产级)
- ✅ 实时数据刷新的性能优化技巧(含测试数据)
- ✅ 可直接复用的代码模板与踩坑预警
咱们直接开干!
🔍 问题深度剖析:为什么ScottPlot在MVVM里这么"难搞"?
根本矛盾:命令式API vs 声明式绑定
ScottPlot本质上是个命令式绘图库,你得手动调Plot. Add. Scatter()、Plot.Refresh()这些方法。但MVVM强调的是声明式数据绑定——ViewModel里数据一变,View自动更新。这就像让一个习惯发号施令的将军去适应民主投票制度,天然有冲突。
我见过最常见的三种错误做法:
错误1:在ViewModel里直接操作WpfPlot控件
csharp// ❌ 这样做彻底违背了MVVM原则
public class BadViewModel
{
public WpfPlot MyPlot { get; set; } // 直接暴露UI控件
public void UpdateData()
{
MyPlot.Plot.Clear(); // ViewModel依赖View层
MyPlot.Plot. Add. Scatter(xData, yData);
MyPlot. Refresh();
}
}
这种写法的问题是ViewModel根本无法单元测试,而且View和ViewModel强耦合,换个UI框架就全废了。
错误2:在后台线程直接刷新图表
csharp// ❌ 跨线程操作UI会抛异常
Task.Run(() => {
wpfPlot. Refresh(); // System.InvalidOperationException
});
错误3:每次数据更新都重建整个图表
csharp// ❌ 性能杀手
private void OnDataChanged()
{
Plot.Clear();
Plot.Add.Scatter(allData); // 10万个点每次都重新添加
Plot.Refresh();
}
在我那个工业监控项目里,这种写法导致刷新一次耗时200ms+,1秒更新5次直接卡成幻灯片。
💡 核心要点提炼:MVVM架构下的设计原则
在正式给方案之前,咱们先理清几个关键点:
1️⃣ 职责分离的黄金法则
- ViewModel:持有数据模型(double[]或ObservableCollection),处理业务逻辑
- View:负责将数据"翻译"成ScottPlot能理解的绘图指令
- 中介者:用
Behavior或附加属性做桥梁(推荐前者)
2️⃣ ScottPlot 5.x 的性能陷阱
新版本的DataSource系统虽然强大,但有个坑:如果你用ObservableCollection直接绑定,每次Add/Remove都会触发全量重绘。正确做法是用ScottPlot.DataSources. ScatterSourceDoubleArray,然后手动控制刷新时机。
3️⃣ 线程安全的铁律
- 数据采集可以在后台线程
- 更新
DataSource必须在UI线程(或用锁保护) Refresh()调用必须在UI线程
在现代应用开发中,高并发和高可用性是客户最为关注的性能指标。而Redis,作为一种优秀的内存数据库,凭借其卓越的性能优势与数据结构,成为了许多开发者的得力助手。然而,很多开发者在使用Redis的过程中,由于缺乏深入的理解,常常会陷入性能瓶颈和数据一致性的问题中。 本文将深入剖析如何在C#开发中高效使用Redis,提升你应用的性能与稳定性。
💡 主体内容
🔍 问题分析
在开发过程中,尤其是面对用户请求激增时,后端数据库的响应速度往往成为了性能瓶颈。传统的关系型数据库在处理大量读写请求时,容易导致慢查询和锁竞争,这时Redis的引入便显得尤为重要。然而,许多开发者在使用Redis时,常常面临以下几个痛点:
- 数据一致性:直接缓存数据库中的数据,往往导致数据在更新时出现不同步的情况。
- 连接管理:频繁建立与断开Redis连接会消耗资源,影响应用性能。
- 使用复杂性:对Redis数据结构不够了解,造成代码可读性差,维护困难。
🛠️ 解决方案
针对以上问题,我们可以采取以下解决方案:
- 引入合适的缓存策略:采用合适的数据易失策略,比如LRU (Least Recently Used) 缓存策略,来确保内存利用率。
- 使用单例模式管理Redis连接:通过单例模式,确保应用在整个生命周期内只与Redis建立一次连接,从而提升性能。
- 保持数据同步:使用消息队列或者发布/订阅模式,确保缓存与数据库的一致性。
💻 代码实战
下面是一个完整的C# Redis使用示例,展示如何实现一个简单的Redis服务,以解决上述提到的问题。
接口
c#using StackExchange.Redis;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace AppRedisService
{
/// <summary>
/// Redis缓存服务接口
/// </summary>
public interface IRedisService : IDisposable
{
/// <summary>
/// 连接状态
/// </summary>
bool IsConnected { get; }
// 字符串操作
Task<T?> GetAsync<T>(string key, CancellationToken cancellationToken = default) where T : class;
Task<string?> GetStringAsync(string key, CancellationToken cancellationToken = default);
Task<bool> SetAsync<T>(string key, T value, TimeSpan? expiry = null, CancellationToken cancellationToken = default);
Task<bool> SetStringAsync(string key, string value, TimeSpan? expiry = null, CancellationToken cancellationToken = default);
// 哈希操作
Task<T?> HashGetAsync<T>(string hashKey, string field, CancellationToken cancellationToken = default) where T : class;
Task<bool> HashSetAsync<T>(string hashKey, string field, T value, CancellationToken cancellationToken = default);
Task<Dictionary<string, T>> HashGetAllAsync<T>(string hashKey, CancellationToken cancellationToken = default) where T : class;
Task<bool> HashDeleteAsync(string hashKey, string field, CancellationToken cancellationToken = default);
// 列表操作
Task<long> ListPushAsync<T>(string key, T value, CancellationToken cancellationToken = default);
Task<T?> ListPopAsync<T>(string key, CancellationToken cancellationToken = default) where T : class;
Task<List<T>> ListRangeAsync<T>(string key, long start = 0, long stop = -1, CancellationToken cancellationToken = default) where T : class;
// 集合操作
Task<bool> SetAddAsync<T>(string key, T value, CancellationToken cancellationToken = default);
Task<bool> SetRemoveAsync<T>(string key, T value, CancellationToken cancellationToken = default);
Task<List<T>> SetMembersAsync<T>(string key, CancellationToken cancellationToken = default) where T : class;
Task<bool> SetContainsAsync<T>(string key, T value, CancellationToken cancellationToken = default);
// 通用操作
Task<bool> KeyExistsAsync(string key, CancellationToken cancellationToken = default);
Task<bool> KeyDeleteAsync(string key, CancellationToken cancellationToken = default);
Task<long> KeyDeleteAsync(IEnumerable<string> keys, CancellationToken cancellationToken = default);
Task<bool> KeyExpireAsync(string key, TimeSpan expiry, CancellationToken cancellationToken = default);
Task<TimeSpan?> KeyTimeToLiveAsync(string key, CancellationToken cancellationToken = default);
// 发布订阅
Task<long> PublishAsync<T>(string channel, T message, CancellationToken cancellationToken = default);
Task SubscribeAsync<T>(string channel, Func<string, T, Task> handler, CancellationToken cancellationToken = default) where T : class;
Task UnsubscribeAsync(string channel, CancellationToken cancellationToken = default);
// 事务操作
Task<bool> ExecuteTransactionAsync(Func<ITransaction, Task> operations, CancellationToken cancellationToken = default);
// 锁操作
Task<IDisposable?> AcquireLockAsync(string lockKey, TimeSpan expiry, CancellationToken cancellationToken = default);
}
}
说实话,我见过太多WinForm项目写着写着就变成了"意大利面条"——按钮点击事件里塞了几百行代码,窗体之间互相调用乱成一团,改一个小功能牵一发动全身。
前阵子接手一个老项目维护,光是一个btnSave_Click事件就写了800多行,里面又是数据校验、又是业务逻辑、还夹杂着UI更新。每次改需求都像在拆炸弹,小心翼翼生怕哪根线接错了。
这篇文章能帮你解决什么?
- 彻底理解事件驱动的核心机制,知其然更知其所以然
- 掌握3种渐进式的事件解耦方案,从简单到复杂逐步升级
- 拿到可直接复用的代码模板,明天就能用在项目里
咱们开始吧。
💡 问题深度剖析:事件处理的三大致命伤
1️⃣ 事件处理器臃肿——"万能方法"综合症
很多开发者习惯把所有逻辑都塞进事件处理器:
csharpprivate void btnSubmit_Click(object sender, EventArgs e)
{
// 数据校验(50行)
// 业务计算(100行)
// 数据库操作(80行)
// UI状态更新(30行)
// 日志记录��20行)
// ... 还在继续
}
我统计过一个真实项目:单个事件处理器平均代码行数达到了247行,最长的一个居然有1200行。这种代码,测试怎么写?复用怎么搞?新人接手直接崩溃。
2️⃣ 窗体耦合严重——"你中有我"困境
窗体A要通知窗体B更新数据,最常见的做法:
csharp// 在FormA中直接操作FormB
FormB formB = Application.OpenForms["FormB"] as FormB;
if (formB != null)
{
formB.RefreshData(); // 直接调用FormB的方法
formB.lblStatus.Text = "已更新"; // 甚至直接操作控件!
}
这种写法的问题在于:FormA必须知道FormB的存在,知道它有哪些方法、哪些控件。一旦FormB重��,FormA也得跟着改。耦合度高到离谱。
3️⃣ 内存泄漏隐患——被遗忘的事件订阅
这是个隐藏很深的坑。事件订阅如果不取消,会导致对象无法被垃圾回收:
csharppublic class DataService
{
public event EventHandler DataChanged;
}
public partial class ChildForm : Form
{
private DataService _service;
public ChildForm(DataService service)
{
_service = service;
_service.DataChanged += OnDataChanged; // 订阅了
// 窗体关闭时忘记取消订阅...
}
}
我用内存分析工具检测过一个项目,因为事件未取消订阅导致的内存泄漏高达127MB,用户反馈程序用久了就变卡,根源就在这儿。
