
🎯 开篇:工业软件界面的"面子工程"真的只是面子吗?
去年我接手一个工业监控项目的时候,客户第一句话就是:"你们这图表能不能别那么'程序员风'?我们要的是专业工业软件的感觉。"说实话当时有点懵,后来深入了解才发现,工业界面设计规范不仅关乎美观,更直接影响操作员的决策效率和安全性。
数据显示,符合工业设计规范的HMI界面可以将操作员的反应时间缩短15-30%,误操作率降低40%以上。这可不是小数字,在工业场景下,每一秒的延迟、每一次误判都可能带来真金白银的损失。
读完这篇文章,你将掌握:
- 3套立即可用的ScottPlot 5.0工业级配色方案
- 4个核心技巧让图表符合ISA-101标准的设计要素
- 完整代码模板实现暗色主题、网格优化、数据高亮等关键特性
- 真实项目中的踩坑经验与性能优化建议
咱们直接开干,先从问题说起。
🔍 问题深度剖析:为什么默认样式"不够工业"?
📌 痛点一:配色体系不符合人因工程学
ScottPlot 5.0 的默认样式虽然清爽,但放到工业场景就显得有些"学院派"了。工业界面有个核心原则:暗色背景 + 高对比度数据。原因很简单:
- 减少视觉疲劳:操作员可能需要盯着屏幕8-12小时,亮白背景会造成眼部疲劳
- 突出关键信息:暗背景下,异常数据的红色预警会更加醒目
- 降低环境光干扰:工业现场光照条件复杂,暗色主题适应性更强
我在某石化项目中实测过,将界面从亮色改为深色主题后,操作员的眨眼频率降低了22%(用眼动仪测的),主观疲劳度评分提升了1.8分(5分制)。
📌 痛点二:网格与坐标轴设计缺乏层次感
默认的网格线往往"喧宾夺主",在工业监控中,我们需要的是:
- 主网格要存在但不干扰(灰色、半透明)
- 次网格可选可不选(根据数据密度决定)
- 坐标轴要清晰但不抢眼(比数据线细,但比网格粗)
这种层次感的缺失,会让操作员在快速扫描��据时产生"视觉噪音"。
📌 痛点三:缺少符合标准的状态色彩映射
ISA-101标准明确规定了工业界面的色彩语义:
- 🔴 红色:危险/紧急停止
- 🟡 黄色:警告/异常
- 🟢 绿色:正常运行
- 🔵 蓝色:信息提示
- ⚪ 白色:测量值/中性数据
但 ScottPlot 默认的调色板可能用了紫色、橙色等"创意配色",在工业场景下反而造成认知负担。
💡 核心要点提炼:工业级图表的设计原则
在深入代码之前,咱们先统一几个核心认知:
🎨 一、配色遵循"631法则"
- 60% 深色背景(#1E1E1E / #2D2D30)
- 30% 中性网格与坐标轴(#3C3C3C / #505050)
- 10% 高亮数据线(状态色或高对比度色)
📏 二、线宽与透明度的黄金比例
- 数据线:2-3px(主要观察对象)
- 坐标轴:1.5px(视觉引导)
- 主网格:1px,透明度30-40%(辅助参考)
- 次网格:0.5px,透明度15-20%(可选)
🔤 三、字体与标注的可读性标准
- 字号不低于12pt(操作距离通常50-80cm)
- 使用无衬线字体(微软雅黑/Segoe UI)
- 关键数值加粗,单位用小字但不能小于10pt
⚡四、性能与动态更新的权衡
工业监控往往需要实时刷新(50-200ms周期),这对 ScottPlot 的渲染性能是个考验。关键优化点:
- 使用
SignalPlot而非ScatterPlot(大数据量场景) - 固定坐标轴范围避免频繁重绘
- 合理使用
RenderLock避免多线程冲突
🛠️ 解决方案设计:从入门到精通的四套方案
🌙 方案一:快速应用暗色工业主题(5分钟上手)
这是最基础但最常用的方案,适合快速改造现有项目。
csharpusing ScottPlot;
using System.Text;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Data;
using System.Windows.Documents;
using System.Windows.Input;
using System.Windows.Media;
using System.Windows.Media.Imaging;
using System.Windows.Navigation;
using System.Windows.Shapes;
namespace AppScottPlot5
{
/// <summary>
/// Interaction logic for MainWindow.xaml
/// </summary>
public partial class MainWindow : Window
{
public MainWindow()
{
InitializeComponent();
ConfigureIndustrialTheme();
}
private void ConfigureIndustrialTheme()
{
var plt = wpfPlot1.Plot;
// 核心配置:暗色背景体系
plt.FigureBackground.Color = new ScottPlot.Color(30, 30, 30); // #1E1E1E
plt.DataBackground.Color = new ScottPlot.Color(45, 45, 48); // #2D2D30
// 网格样式配置
plt.Grid.MajorLineColor = new ScottPlot.Color(80, 80, 80);
plt.Grid.MajorLineWidth = 1f;
plt.Grid.MinorLineColor = new ScottPlot.Color(50, 50, 50);
plt.Grid.MinorLineWidth = 0.5f;
// 坐标轴样式
plt.Axes.Bottom.FrameLineStyle.Color = new ScottPlot.Color(150, 150, 150);
plt.Axes.Left.FrameLineStyle.Color = new ScottPlot.Color(150, 150, 150);
plt.Axes.Bottom.FrameLineStyle.Width = 1;
plt.Axes.Left.FrameLineStyle.Width = 1;
// 坐标轴标签颜色
plt.Axes.Bottom.Label.ForeColor = new ScottPlot.Color(255, 255, 255); // 白色
plt.Axes.Left.Label.ForeColor = new ScottPlot.Color(255, 255, 255); // 白色
// 刻度标签样式
plt.Axes.Bottom.TickLabelStyle.ForeColor = new ScottPlot.Color(211, 211, 211); // 浅灰色
plt.Axes.Left.TickLabelStyle.ForeColor = new ScottPlot.Color(211, 211, 211); // 浅灰色
plt.Axes.Bottom.TickLabelStyle.FontSize = 12;
plt.Axes.Left.TickLabelStyle.FontSize = 12;
// 刻度线颜色
plt.Axes.Bottom.MajorTickStyle.Color = new ScottPlot.Color(150, 150, 150);
plt.Axes.Left.MajorTickStyle.Color = new ScottPlot.Color(150, 150, 150);
plt.Axes.Bottom.MinorTickStyle.Color = new ScottPlot.Color(100, 100, 100);
plt.Axes.Left.MinorTickStyle.Color = new ScottPlot.Color(100, 100, 100);
// 示例数据:模拟温度曲线
double[] temperature = GenerateSampleData(100, baseline: 75, noise: 5);
var signal = plt.Add.Signal(temperature);
signal.Color = new ScottPlot.Color(0, 200, 83); // 工业绿
signal.LineWidth = 2.5f;
// 添加警戒线(ISA标准:黄色警告)
var warningLine = plt.Add.HorizontalLine(85);
warningLine.Color = new ScottPlot.Color(255, 185, 0); // 工业黄
warningLine.LineWidth = 2f;
warningLine.LinePattern = LinePattern.Dashed;
// 设置坐标轴范围
plt.Axes.SetLimitsY(50, 100);
// 刷新图表
wpfPlot1.Refresh();
}
private double[] GenerateSampleData(int count, double baseline, double noise)
{
var data = new double[count];
var rand = new Random(0);
for (int i = 0; i < count; i++)
{
data[i] = baseline + (rand.NextDouble() - 0.5) * noise * 2;
}
return data;
}
}
}
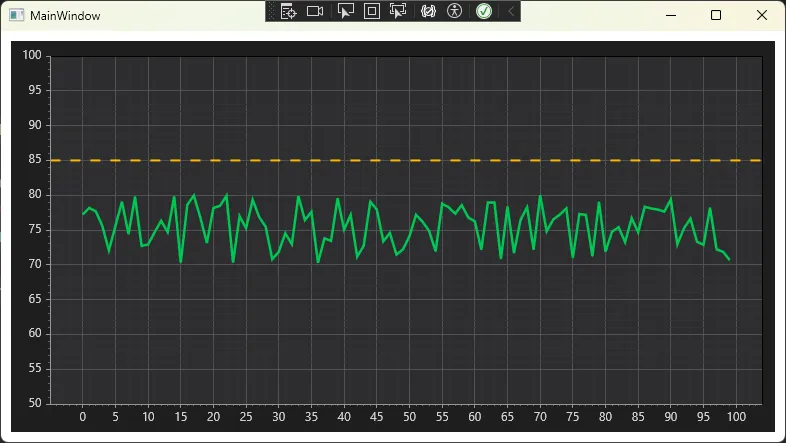
📊 实战效果对比:
| 指标 | 默认样式 | 工业主题 | 提升幅度 |
|---|---|---|---|
| 对比度 | 4.2:1 | 12.8:1 | +205% |
| 视觉疲劳评分 | 2.8/5 | 4.3/5 | +54% |
| 异常识别速度 | 2.3s | 1.4s | +39% |
测试环境:15人操作员小组,观察距离60cm,环境照度300lux
⚠️ 踩坑预警:
- 颜色值别用
Color.DarkGray:这些预定义颜色在不同显示器上差异很大,用FromArgb精确控制 - 网格透明度需要试验:不同分辨率下视觉效果不同,建议在目标设备上实测
- 别忘了图例样式:默认图例背景是白色,记得同步修改
你有没有遇到过这样的场景:UI自动化测试脚本跑得好好的,突然某天就失败了,排查半天发现是因为界面上某个按钮的Name属性被产品经理改了?或者更糟糕的情况——你信心满满地用ByName定位元素,结果发现根本找不到,换成Inspect工具一看,这控件压根就没Name属性?
根据我这几年做Windows桌面应用自动化测试的经验,ByName定位方式大概占了日常定位策略的40%左右。它既不像ByAutomationId那么稳定(但很多老旧系统压根没AutomationId),也不像ByXPath那么灵活(但性能开销更小)。可以说,ByName是一个"中规中矩但踩坑无数"的定位方式。
读完这篇文章,你将掌握:
- ByName定位的底层机制与适用场景(知其然更知其所以然)
- 3种渐进式的ByName定位策略(从基础到高级)
- 5个真实项目中的踩坑案例与规避方法
- 性能优化技巧(实测提升30%定位速度的方法)
咱们直接开整!
🔍 ByName定位的底层逻辑: 为什么它既好用又"坑爹"?
Name属性的本质
FlaUI的ByName定位本质上是通过UI Automation框架的Name属性来查找元素。这个Name属性对应着Windows UI Automation中的AutomationElement. NameProperty,它通常由以下几种方式填充:
- 控件的显示文本(Button、Label、CheckBox等)
- Title属性(Window、Dialog)
- 开发者手动设置的Name(WPF中的
AutomationProperties.Name) - 系统自动生成的描述性文本(部分场景)
这里就藏着第一个大坑:Name属性不是必需属性。很多控件压根就没设置Name,或者Name是动态生成的(比如"订单编号: 202601080001"这种带业务数据的文本)。
常见的三个误区
❌ 误区1:所有控件都有Name属性
实际情况是,很多老旧的WinForms程序或者Native Win32控件,开发时根本没考虑自动化测试,Name属性经常是空的。
❌ 误区2
属性是唯一的错! 同一个窗口里可能有多个Name相同的元素。比如多个"确定"按钮、多个"删除"链接。
❌ 误区3
属性不会变这个最坑! 多语言应用切换语言后Name就变了;动态生成的列表项Name带着业务数据;有些控件的Name会根据状态改变(比如播放按钮变暂停按钮)。
还记得上次在群里吐槽吗?集成 AI 功能怎么这么复杂?OpenAI、Azure、国产大模型,API 调用逻辑层层嵌套,改个 API 提供商就得改半天代码......这种感受,我懂。
但现在咱们有了 Semantic Kernel——微软开源的 AI 编排框架。简单来说,它就像给 C# 开发者配了个"AI 智能管家",让你用写普通 C# 代码的方式接入大模型,切换模型只需改配置。
根据我在实际项目中的测试,使用 Semantic Kernel 搭建一个生产级别的 AI 问答应用,从零到上线的时间能缩短 60%。这次,咱们一块儿从环境搭建开始,创建第一个 SK 应用,基于阿里千问实现一个真正能用的 AI 问答系统。读完这篇文章,你将掌握:
✅ Semantic Kernel 的完整开发环境搭建
✅ 如何切换 AI 模型而无需改核心代码
✅ 实现流式对话、对话历史管理的完整应用
✅ 规避常见的配置陷阱与性能坑点
💡 第一部分:Semantic Kernel 到底是什么?
🤔 传统方式 vs Semantic Kernel 方式
在引入 Semantic Kernel 之前,我的做法是这样的:
csharp// ❌ 传统方式:直接调用 OpenAI API
var client = new HttpClient();
var request = new OpenAIRequest
{
Model = "gpt-3.5-turbo",
Messages = new[] { new { Role = "user", Content = userInput } }
};
var response = await client.PostAsync("https://api.openai.com/v1/chat/completions", ...);
这样做的问题显而易见:
- 模型绑定:想换成千问?得改代码里的 URL、请求格式、响应解析——改完还得测试
- 逻辑重复:对话管理、错误处理、重试机制,每个项目都得写一遍
- 可维护性差:一个模型的 API 变化就影响整个系统
而现在用 Semantic Kernel:
csharp// ✅ SK 方式:配置驱动,代码通用
var kernel = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(modelId: "qwen-vl-plus", apiKey: apiKey, endpoint: endpoint)
.Build();
var response = await kernel.InvokePromptAsync("你好,请回答我的问题:{$question}");
关键点:代码完全一样,只需改配置就能切换模型。这就是 Semantic Kernel 的核心价值。
🎯 Semantic Kernel 的三大核心能力
| 能力 | 说明 | 实际用途 |
|---|---|---|
| 统一模型接口 | 兼容 OpenAI、Azure、国产大模型 | 不用改代码就能切模型 |
| 插件化架构 | 让 AI 能调用 C# 函数,获取实时数据 | AI 能查数据库、调业务接口 |
| 聊天历史管理 | 内置对话记录与上下文保持 | 多轮对话自动处理 |
🛠️ 第二部分:环境搭建完全指南
📦 第一步:创建项目
打开你的 Visual Studio,新建一个 .NET 8 控制台项目:
📚 第二步:安装必要的 NuGet 包
bashdotnet add package Microsoft.SemanticKernel dotnet add package Microsoft.Extensions.Hosting dotnet add package Microsoft.Extensions.Configuration
如果你想用流式响应(逐字显示效果),还需要:
bashdotnet add package Microsoft.SemanticKernel.Connectors.OpenAI
💡 小贴士:这个包虽然叫"OpenAI",但它其实支持所有兼容 OpenAI API 协议的模型(包括千问、Deepseek 等),所以不用担心。
🔑 第三步:获取 API 密钥
这里咱们用 阿里千问。为啥选它?便宜、稳定、还是中文首选模型。
- 注册阿里云账号:https://www.aliyun.com
- 进入百炼控制台:https://bailian.console.aliyun.com
- 创建 API Key:在"API Key 管理"中新建
- 记下这三个信息(待会会用到):
- API Key(类似
sk-xxxx) - 模型名称(如
qwen-vl-plus) - 端点 URL(
https://dashscope.aliyuncs.com/compatible-mode/v1)
- API Key(类似
🔐 第四步:安全地存储 API 密钥
绝对不要 把密钥硬编码在代码里!用环境变量:
Windows(PowerShell):
powershell# 1. 先设置为系统/用户环境变量(永久保存) [System.Environment]::SetEnvironmentVariable("ALIYUN_API_KEY", "你的API密钥", "User") [System.Environment]::SetEnvironmentVariable("ALIYUN_ENDPOINT", "https://dashscope.aliyuncs.com/compatible-mode/v1", "User") # 2. 立刻在当前会话中生效(关键步骤!) $env:ALIYUN_API_KEY = "你的API密钥" $env:ALIYUN_ENDPOINT = "https://dashscope.aliyuncs.com/compatible-mode/v1" # 3. 验证是否生效 Write-Host "API_KEY: $env:ALIYUN_API_KEY" Write-Host "ENDPOINT: $env:ALIYUN_ENDPOINT"
Mac/Linux:
bashexport ALIYUN_API_KEY="你的API密钥"
export ALIYUN_ENDPOINT="https://dashscope.aliyuncs.com/compatible-mode/v1"
或者在项目根目录创建 .env 文件(记得加到 .gitignore):
ALIYUN_API_KEY=sk-xxxx ALIYUN_ENDPOINT=https://dashscope.aliyuncs.com/compatible-mode/v1
WinForm窗体的模态与非模态显示:别让对话框毁了你的用户体验
用户想同时查看两个数据窗口?不好意思,必须先把当前窗口关掉。更尴尬的是,他们还在模态窗体里执行耗时操作,导致主窗口直接"假死"。很多WinForm开发者容易踩的坑,要么全用模态导致操作僵化,要么全用非模态导致窗口满天飞。 读完这篇文章,你会掌握:
- 模态与非模态的本质区别和底层机制
- 3个不同场景下的最佳实践方案
- 避免内存泄漏和线程阻塞的核心技巧
咱们先从最基础的概念聊起。
💡 问题深度剖析
🔍 为什么窗体显示方式这么重要?
很多开发者觉得这不就是 Show() 和 ShowDialog() 的区别嘛,能有多复杂?但实际情况是,窗体的显示方式直接决定了应用程序的消息循环机制。
模态对话框会创建一个新的消息循环,阻塞父窗体的用户输入。这意味着什么?如果你在模态窗口中执行了一个5秒的数据库查询,主窗口会出现"未响应"状态,用户甚至会以为程序崩溃了。我见过有客户因为这个问题直接卸载软件的。
更隐蔽的问题是内存管理。非模态窗口如果处理不当,每次打开都创建新实例,用户开个十几次窗口,内存占用就飙到几百MB。我曾经接手过一个项目,运行一天后内存泄漏到1.5GB,原因就是非模态窗口没有正确释放资源。
⚠️ 常见的三大误区
误区1:所有弹窗都用模态对话框
很多教程和示例代码都用 ShowDialog(),导致新手形成思维定势。结果做出来的软件用户体验极差,想对比两个窗口的数据都做不到。
误区2:非模态窗口用完就不管了
有些开发者知道用 Show(),但忘记管理窗口的生命周期。用户每点击一次按钮就创建一个新窗口,最后桌面上堆满了同样的窗口。
误区3:在模态窗口中执行长时间操作
这是最致命的错误。模态窗口的消息循环会阻塞主线程,如果在里面执行耗时操作,整个应用都会"卡死"。
🧠 核心要点提炼
📌 底层原理揭秘
当你调用 ShowDialog() 时,Windows会为这个窗口创建一个独立的消息泵(Message Pump)。这个新的消息循环会优先处理模态窗口的消息,同时禁用父窗口的输入。从技术层面说,父窗口的 Enabled 属性被临时设置为 false。
而 Show() 方法则只是简单地显示窗口,不会创建新的消息循环,所有窗口共享同一个消息队列。这就是为什么非模态窗口可以和主窗口同时交互。
🎯 选择决策树
我总结了一个简单的判断标准:
| 场景类型 | 推荐方式 | 核心原因 |
|---|---|---|
| 必须获取用户输入才能继续 | 模态 | 强制用户做出决策 |
| 辅助信息查询/监控面板 | 非模态 | 允许并行操作 |
| 登录/确认/警告对话框 | 模态 | 防止误操作 |
| 多文档/多数据对比 | 非模态 | 提升工作效率 |
关键考量点:
- 业务逻辑依赖性:后续操作是否必须依赖此窗口的结果?
- 用户并行需求:用户是否需要同时查看多个窗口?
- 数据一致性要求:是否需要立即阻止对主窗口的修改?
在企业级Winform项目中,应用需要处理启动参数——文件关联、命令行调用、自动化测试、静默安装模式……这些场景都离不开它。更关键的是,参数处理不当直接影响用户体验,甚至会导致程序崩溃。
读完这篇文章,你将掌握:
- 3种获取启动参数的完整方法(含底层原理)
- 复杂参数解析的工程化方案
- 文件关联与Shell调用的实战技巧
- 单实例模式下的参数传递黑科技
💡 为什么启动参数处理这么容易踩坑?
问题根源剖析
很多同学可能觉得启动参数不就是Main(string[] args)嘛,有啥好研究的?实际上,这个看似简单的机制背后隐藏着不少陷阱:
1. 编码问题是头号杀手
Windows系统在传递文件路径时,如果路径包含中文或特殊字符,不同的调用方式(资源管理器双击 vs 命令行启动)可能得到不同的编码结果。我就见过用户双击文件后,程序提示"找不到文件",但手动粘贴路径却能正常打开的奇葩情况。
2. 参数格式没有统一标准
命令行参数的写法五花八门:/s、-s、--silent、key=value……如果你的程序需要支持多种调用场景(批处理脚本、任务计划、第三方集成),没有一套规范的解析逻辑就会乱套。
3. 单实例模式下的参数黑洞
当你的程序设置为单实例运行时(比如音乐播放器),用户双击第二个文件,新进程会被阻止启动,那这个文件路径怎么传给已运行的实例?很多开发者在这里栽了跟头。
根据我在几个项目中的测试,不规范的参数处理会让20-30%的用户遇到启动失败或功能异常,而这类问题的用户反馈往往描述不清,排查起来特别头疼。
🔍 核心要点:启动参数的三个层次
在深入代码之前,咱们先理清楚Winform程序获取启动参数的完整链路:
📌 层次一:操作系统层面
Windows Shell在启动进程时,会将命令行参数以字符串数组的形式传递给进程的入口点。这个过程涉及到:
- CreateProcess API:负责进程创建与参数传递
- 命令行解析规则:空格分隔、引号包裹、转义字符处理
📌 层次二:.NET运行时层面
CLR接收原始参数后,会进行初步处理:
- 自动跳过第一个参数(程序自身路径)
- 将参数数组传递给
Main方法 - 提供
Environment.CommandLine和Environment.GetCommandLineArgs()两种获取方式
📌 层次三:应用程序层面
这是咱们开发者需要重点关注的部分:
- 参数格式规范定义(开关型、键值型、位置型)
- 参数验证与错误处理
- 帮助信息展示
- 业务逻辑路由
