
说实话,FTP 这个协议老得像古董,但在工业控制、内网文件同步这些场景里,它活得比你想象中滋润多了。前段时间我用 WinForms + C# 写了一个完整的 FTP 客户端,从连接管理、异步目录浏览,到带断点续传的传输队列,把能踩的坑基本都踩了一遍。今天把核心设计思路和几个关键实现细节掰开揉碎说给你听。
🏗️ 先聊架构——别把所有逻辑塞进 Form 里
很多人写 WinForms 项目,最后 FrmMain.cs 膨胀到几千行,UI 逻辑、业务逻辑、数据访问全搅在一起。这玩意儿后期维护起来,真的是一种折磨。
这个项目我拆成了三层:
Core层:FTPClient(协议通信)、ConnectionManager(连接历史管理)、FileTransfer(传输队列调度)Models层:纯数据模型,FTPConnection、TransferTask、FileItem等Forms层:只负责 UI 呈现和用户交互,不碰业务逻辑
FrmMain 的构造函数里,三个核心对象各司其职:
csharp_ftpClient = new FTPClient();
_connectionManager = new ConnectionManager();
_fileTransfer = new FileTransfer(_ftpClient);
FileTransfer 依赖注入 FTPClient,这样测试和替换都方便。简单。干净。
👨💻先看效果
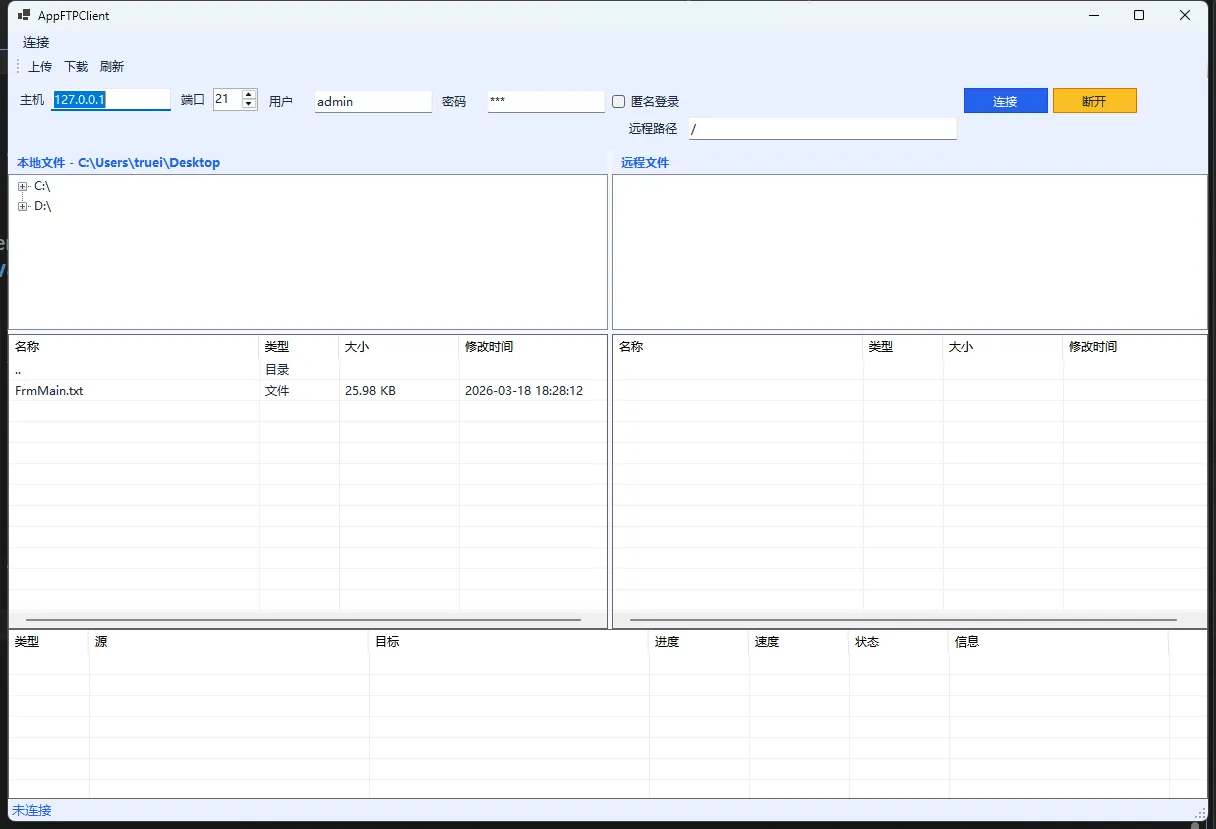
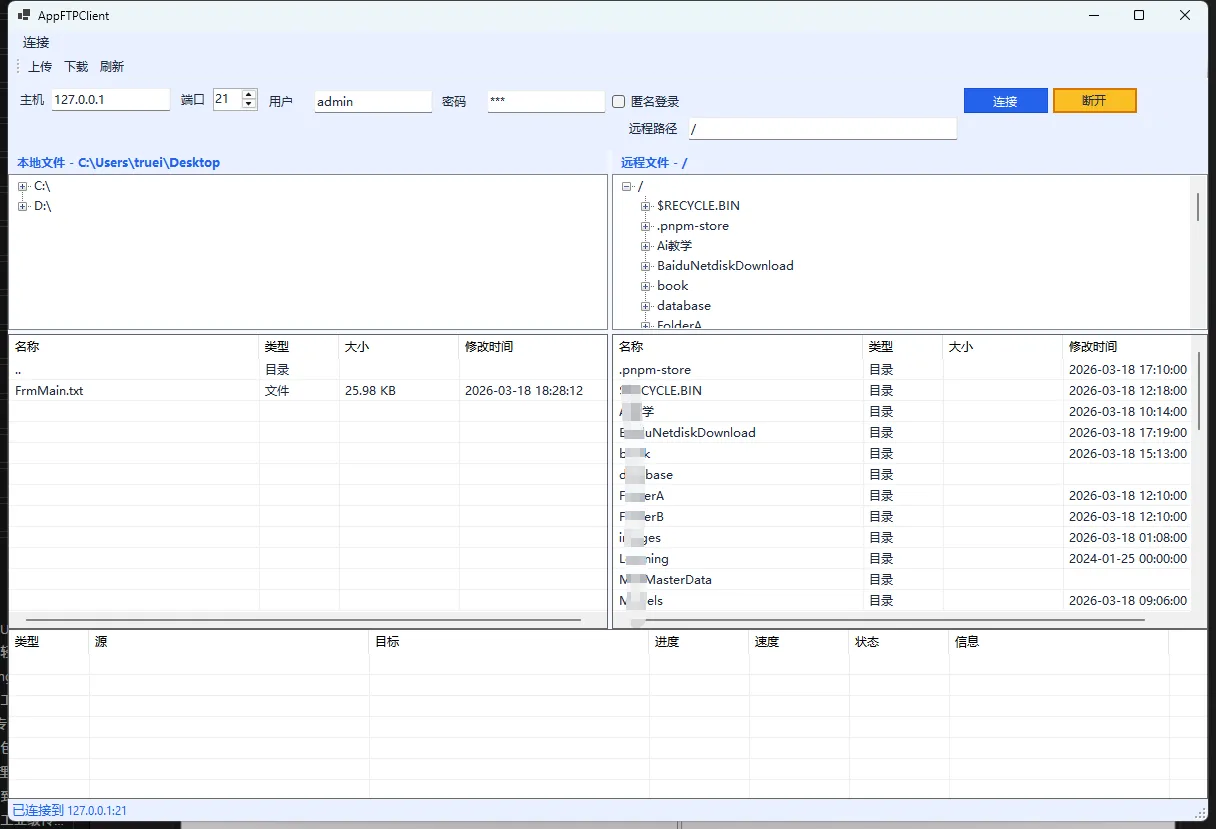
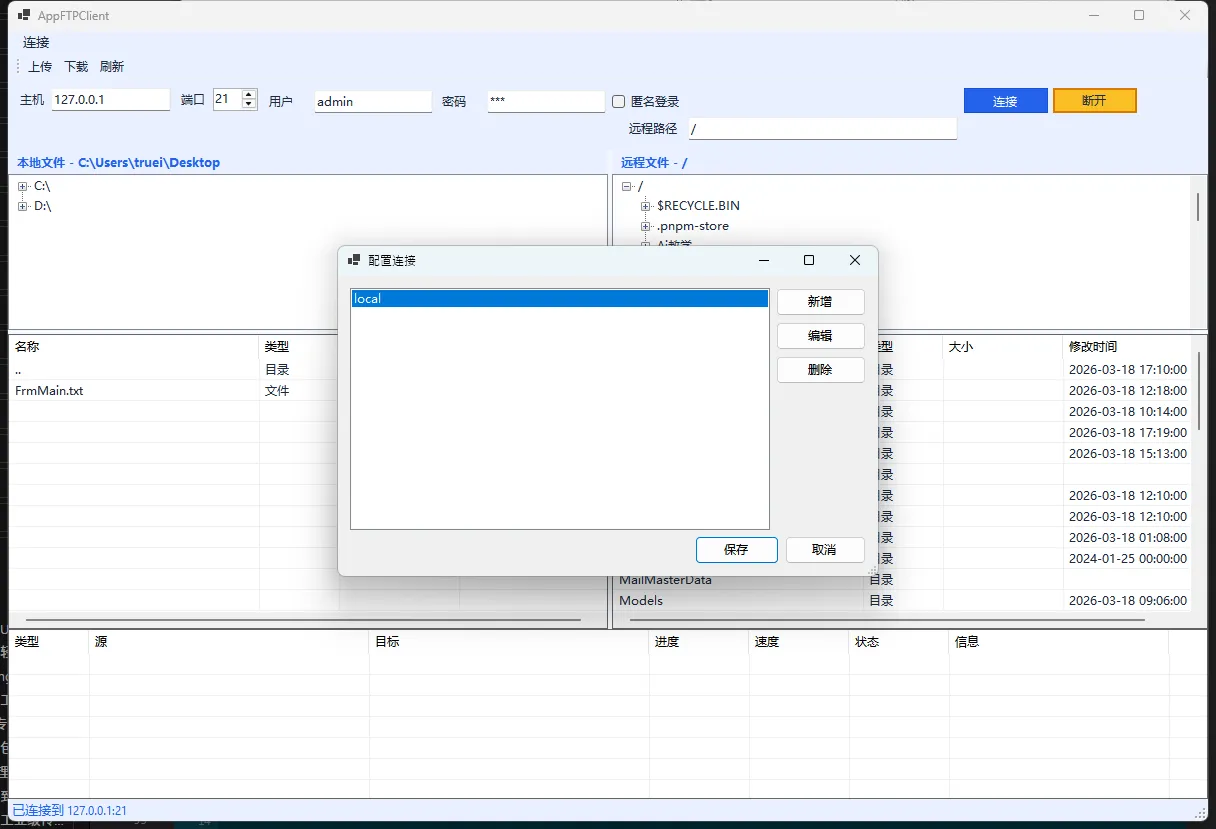
作为一个码农,我敢打赌你一定遇到过这样的场景——需要让不同的程序之间"聊聊天"。可能是客户端需要实时获取服务器数据,也可能是多个应用需要协同工作。Socket通信就像是程序世界的"微信",让各个应用能够畅快地交流。
但现实总是残酷的。Socket编程对很多开发者来说就像是一座大山——概念抽象、异步复杂、错误处理繁琐。我见过太多项目因为网络通信问题而延期,也看过不少开发者被TCP/UDP折腾得焦头烂额。
今天这篇文章的价值承诺很简单:通过一个完整的WPF Socket通信应用实例,让你彻底掌握C#网络编程的核心技巧,从此告别"网络通信恐惧症"。
🎯 Socket通信的本质:程序间的"对话艺术"
💡 底层原理揭秘
Socket说白了就是网络编程的"插座"。想象一下你家的电器插座——一头连接电源(服务器),另一头连接用电设备(客户端)。Socket也是这样的桥梁,只不过传输的不是电力,而是数据。
在Windows系统中,Socket实际上是对底层WinSock API的封装。每当你创建一个Socket对象时,系统会:
- 分配一个唯一的句柄
- 在内核空间创建对应的数据结构
- 建立用户空间到内核空间的映射关系
这就是为什么Socket操作需要小心处理异常——你在操作的不只是内存中的对象,更是系统资源。
🚀 实战项目剖析:双面Socket应用
我们今天要分析的这个项目很有意思——它把服务器和客户端功能集成在同一个WPF应用中。这样的设计在实际开发中特别有用,比如:
- 开发阶段的调试测试
- 分布式系统的节点程序
- P2P应用的双向通信
🏗️ 整体架构设计
csharp// 核心字段设计 - 服务器部分
private Socket serverSocket; // 服务器监听Socket
private List<Socket> clientSockets; // 客户端连接池
private bool isServerRunning; // 服务器运行状态
// 核心字段设计 - 客户端部分
private Socket clientSocket; // 客户端连接Socket
private bool isClientConnected; // 客户端连接状态
这个设计很巧妙。用一个List<Socket>来管理多个客户端连接,这在真实项目中非常实用——想想QQ群聊,一个服务器要同时处理成百上千个客户端连接。
🎭 服务器端:一夫当关的"管家"
🔥 启动服务器的核心流程
csharpprivate async void btnStartServer_Click(object sender, RoutedEventArgs e)
{
try
{
string ipAddress = txtServerIP.Text.Trim();
int port = int.Parse(txtServerPort.Text.Trim());
// 创建TCP Socket
serverSocket = new Socket(AddressFamily.InterNetwork,
SocketType.Stream,
ProtocolType.Tcp);
IPEndPoint endPoint = new IPEndPoint(IPAddress.Parse(ipAddress), port);
serverSocket.Bind(endPoint); // 绑定地址端口
serverSocket.Listen(100); // 开始监听,队列长度100
isServerRunning = true;
// ... UI状态更新代码
// 异步接受客户端连接
await Task.Run(() => AcceptClientsAsync());
}
catch (Exception ex)
{
LogServerMessage($"✗ 启动失败: {ex.Message}");
}
}
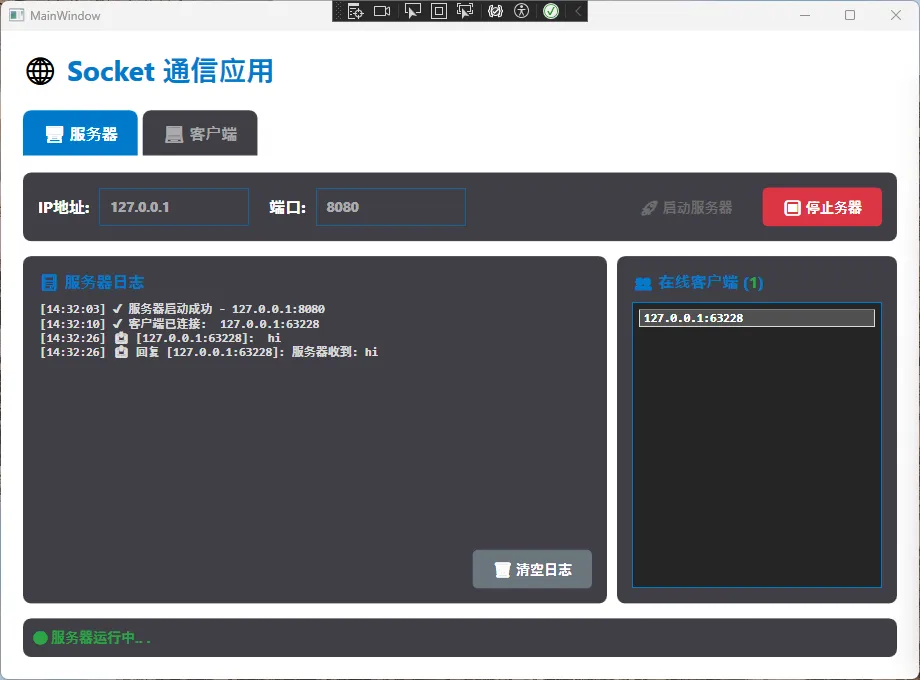
关键点解析:
Listen(100)这个参数很重要!它决定了系统能排队等待处理的连接数量- 使用
Task.Run而不是直接await AcceptClientsAsync(),这样能避免阻塞UI线程 - 异常处理必须做到位——网络操作最容易出问题
🔥 那个让我凌晨三点爬起来修 Bug 的惨痛教训
说一个真实场景。
某电商平台,下单流程是这样的:订单写进数据库,然后发一条消息通知仓储系统备货。看起来天衣无缝,对吧?
然后某天夜里,消息队列抖了一下。订单数据写进去了,消息没发出去。仓储那边压根不知道有新订单,货没备,用户投诉雪片一样飞来。
我那天凌晨三点接到电话,脑子里第一个念头就是:这个 bug,从架构层面就注定会出现。
这不是某个程序员写错了代码。这是"先存数据,再发事件"这种写法,骨子里就带着的缺陷。
今天咱们就把这个问题彻底讲清楚——用 Transactional Outbox 模式,从根上掐断这类事故。
😈 传统写法的三宗罪
先看看大多数项目里长什么样子:
csharp// ❌ 危险写法 —— 看起来没问题,实则暗藏杀机
public async Task PlaceOrderAsync(Order order)
{
await _db.SaveOrderAsync(order); // 第一步:存数据库
await _mq.PublishAsync(order.ToEvent()); // 第二步:发消息
}
就这两行,藏着三个随时能把你坑惨的问题:
第一宗罪:数据存了,消息没发。 第一步成功,第二步网络抖动超时。订单进了库,仓储不知道,下游状态撕裂。
第二宗罪:消息发了,数据没存。 顺序反过来也一样。消息先出去了,数据库写失败回滚,下游收到一个幽灵订单。
第三宗罪:消息重复发。 重试机制触发,同一个事件发了两次,下游扣了两次库存。
这三个问题,本质上是同一件事:两个不同的资源(数据库 + 消息队列)没有纳入同一个事务。CAP 定理告诉我们,分布式系统里这种跨资源的原子性,本来就很难保证。
💡 Outbox 模式:把"发消息"变成"存数据"
核心思路其实挺朴素的——既然数据库事务是可靠的,那就把"发消息"这个动作,也变成一次数据库写入。
写入API │ ├─── INSERT Orders ─┐ │ ├── 同一个数据库事务,要么全成功,要么全失败 └─── INSERT Outbox (事件) ─┘ │ ▼ OutboxProcessor (后台服务) │ ├── SELECT 未处理事件 ├── PublishAsync → 消息队列 └── UPDATE 标记已处理
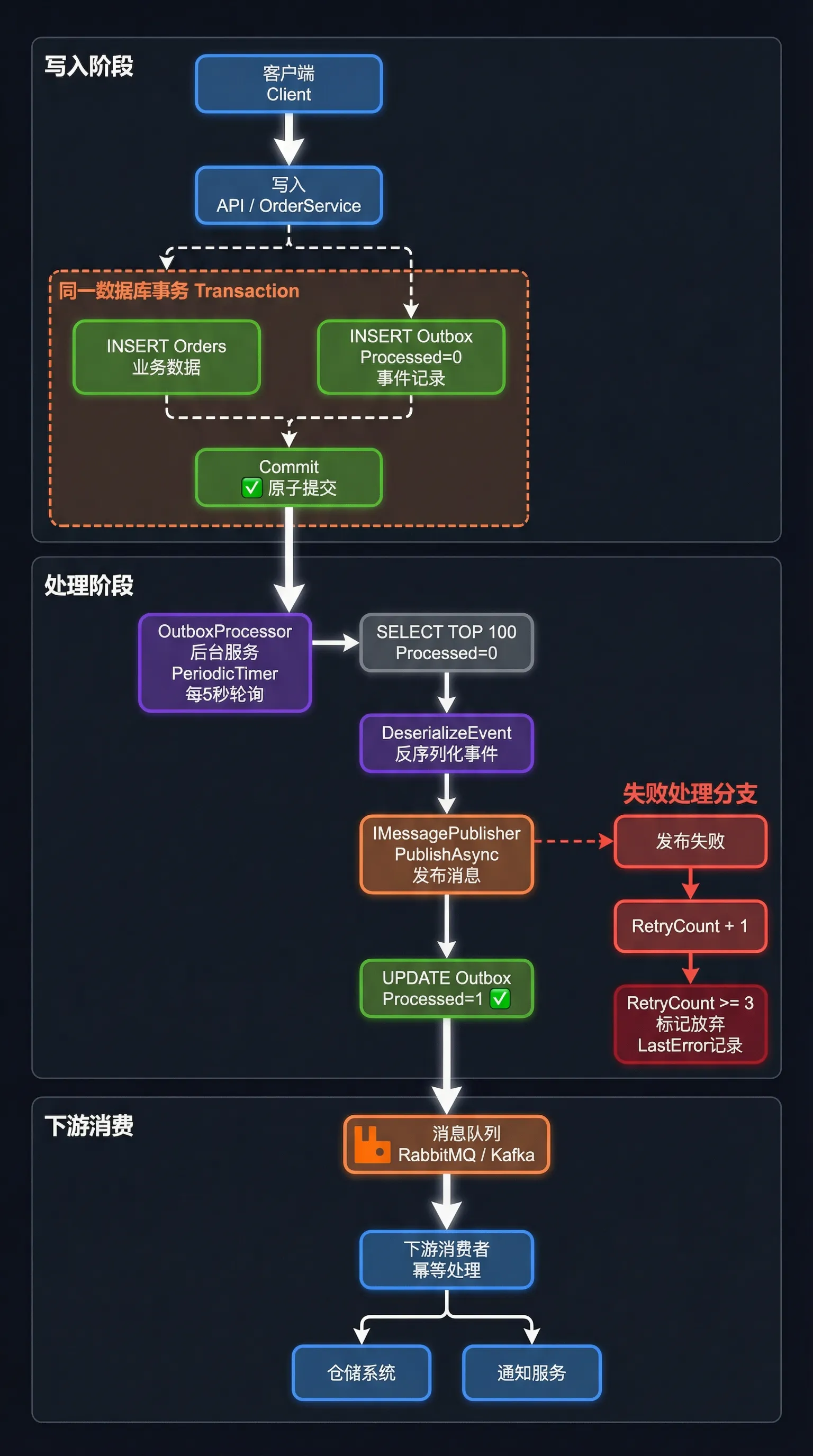
订单和事件一起落库,用同一个事务保证原子性。后台有个处理器轮询 Outbox 表,把事件捞出来发到消息队列。这两步之间哪怕系统崩了,重启之后处理器继续从 Outbox 里捞,一条事件都不会丢。
相信每个C#开发者都遇到过这样的困境:写了一串优雅的LINQ链式调用,结果程序性能急剧下降,内存分配暴增。特别是在游戏开发或高并发场景下,传统LINQ的性能问题让人头疼不已。
今天为大家介绍一个革命性的解决方案——ZLinq,一个真正实现零内存分配的LINQ库,性能比原生LINQ提升数倍到数十倍!
🎯 传统LINQ的性能痛点分析
内存分配黑洞
传统System.Linq每个操作符都会创建新的迭代器对象,方法链越长,分配的对象越多:
c#// 每个方法都会产生装箱和迭代器分配
var result = source
.Where(x => x % 2 == 0) // 分配Where迭代器
.Select(x => x * 3) // 分配Select迭代器
.Take(10); // 分配Take迭代器
性能瓶颈根源
- 迭代器开销:每次MoveNext和Current调用都有虚方法开销
- 装箱拆箱:IEnumerator接口调用产生大量装箱
- 缓存友好性差:多层迭代器嵌套破坏CPU缓存局部性
💡 ZLinq的三大核心优势
🔥 零分配架构设计
ZLinq采用基于结构体的枚举器设计,彻底消除堆分配:
c#using ZLinq;
var source = new int[] { 1, 2, 3, 4, 5 };
// 只需要添加一行AsValueEnumerable()
var result = source
.AsValueEnumerable() // 零分配转换
.Where(x => x % 2 == 0) // 结构体操作符
.Select(x => x * 3) // 无堆分配
.Take(10); // 纯栈操作
foreach (var item in result)
{
Console.WriteLine(item); // 高性能迭代
}
关键技术突破:
- 使用
ValueEnumerable<TEnumerator, T>替代IEnumerable<T> - 结构体枚举器避免虚方法调用
TryGetNext(out T current)合并MoveNext和Current操作
老代码里有50多个窗体,每个窗体平均30个控件,开发人员竟然用的是硬编码:btnSave.Enabled = false; btnDelete.Enabled = false... 一个个写,整个项目光是这类重复代码就超过3000行。
更要命的是,又提出"所有输入框需要统一样式"、"表单数据一键清空"等需求。如果继续用老方法,改一次需求就要修改几百处代码。我当时就在想,这不就是个典型的控件集合批量操作问题吗?
读完这篇文章,你将学会:
- 4种控件遍历方法及其适用场景
- 递归遍历嵌套容器的正确姿势
- 批量操作的高性能封装技巧
咱们从最常见的问题开始聊。
💡 问题深度剖析
🔍 为什么控件遍历这么重要?
很多开发者觉得控件遍历不就是个循环嘛,有啥好讲的?但实际项目中,我见过太多因为遍历方式不当导致的问题:
问题一:漏掉嵌套容器中的控件
新手经常直接 foreach (Control ctrl in this.Controls),结果只能遍历到窗体的直接子控件。如果你的界面用了Panel、GroupBox、TabControl等容器,里面的控件根本遍历不到。我接手的那个医疗系统就有这个问题,导致Panel里的按钮权限控制完全失效。
问题二:性能隐患
曾经见过有人在Form_Load里遍历控件做初始化,每次遍历都用反射判断类型,一个复杂窗体光加载就要2-3秒。用户打开软件等半天白屏,直接以为程序卡死了。
问题三:维护噩梦
硬编码的控件操作分散在代码各处,需求一变动就要全局搜索修改。而且容易漏改,测试阶段各种bug冒出来。
⚠️ 三大常见误区
误区1:用索引访问Controls集合
csharpfor (int i = 0; i < this.Controls.Count; i++)
{
Control ctrl = this.Controls[i];
// 操作控件...
}
这玩意儿看起来没问题,但如果遍历过程中有控件被移除或添加,索引就乱套了。我见过因为这个导致的越界异常,用户点个按钮程序直接崩溃。
误区2:类型判断用字符串比较
csharpif (ctrl.GetType().Name == "TextBox") // 危险!
这种写法不仅性能差,还容易出错。继承自TextBox的自定义控件就识别不出来了。
误区3:递归遍历不考虑深度
有些界面控件嵌套层级很深,无限递归可能导致栈溢出。虽然实际场景比较少见,但在我经手的一个动态生成界面的项目里真的遇到过。
📊 性能影响量化
我做过一���测试,对比不同遍历方式处理500个控件的性能:
| 遍历方式 | 执行时间 | 内存分配 |
|---|---|---|
| 直接foreach | 15ms | 8KB |
| 索引访问 | 18ms | 8KB |
| 递归+类型判断 | 45ms | 25KB |
| 优化后的递归 | 22ms | 12KB |
测试环境:Intel i7-10700 / 16GB RAM / .NET Framework 4.8
可以看出,不当的遍历方式性能差距能达到3倍。在复杂的企业应用中,这种细节累积起来,用户体验差异会非常明显。
