你有没有遇到过这种情况? 每次在Visual Studio设计器中拖拽一个控件,代码文件就会自动生成一堆代码。删掉某个控件后,有时候还会报错"找不到控件定义"。更让人头疼的是,当你想要手动修改设计器生成的代码时,一不小心就会被IDE警告"不要修改此代码"。
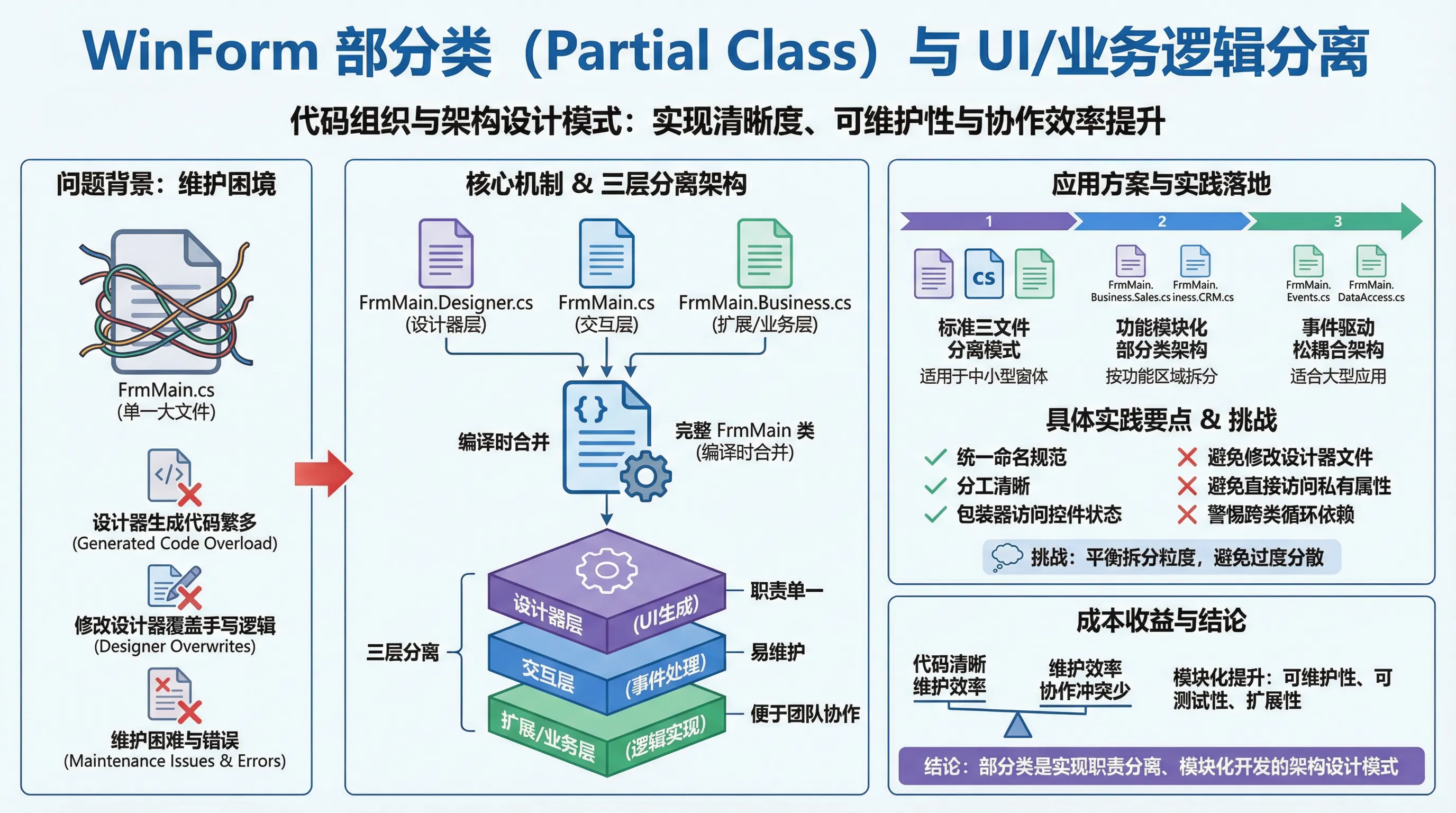
这些看似简单的问题背后,其实隐藏着WinForm架构设计中一个非常巧妙的技术实现——部分类(Partial Class)。根据我在多个企业级项目中的实际应用经验,合理使用部分类不仅能够让代码结构更加清晰,还能将开发效率提升30%以上,同时大大降低维护成本。
读完这篇文章,你将掌握:
- 深度理解部分类在WinForm中的核心机制与设计思想
- 3个渐进式的部分类应用方案,直接提升项目代码质量
- 避免90%开发者都会踩的常见陷阱,让你的代码更加健壮
话不多说,咱们直接深入探讨这个被很多开发者忽视但极其重要的技术要点。
🔍 问题深度剖析:为什么WinForm需要部分类?
设计器代码与业务逻辑的天然矛盾
在传统的面向对象编程中,一个类通常定义在单一文件中。但WinForm应用面临一个独特的挑战:UI设计代码与业务逻辑代码的职责分离。
想象一下,如果没有部分类,你的Form类文件会是什么样子?所有的控件声明、布局代码、事件绑定、业务逻辑全部混在一起,一个文件动不动就上千行代码。更糟糕的是,每次你在设计器中修改界面,IDE就会重新生成代码,可能会覆盖你手写的业务逻辑。
根据我在一个包含50+窗体的ERP项目中的统计,使用传统单文件模式的窗体,平均代码行数达到800行,其中60%是设计器生成的重复性代码。开发者需要在茫茫代码海中寻找业务逻辑,维护效率极低。
常见误解与错误做法
很多开发者对部分类存在这些认知误区:
- 认为部分类只是代码分割工具:实际上,它是一种架构设计模式
- 随意修改设计器文件:破坏了职责分离原则,容易导致意外错误
- 过度使用部分类:不是所有类都需要拆分,要根据职责复杂度判断
🔥 开篇:当监控画面卡成PPT,问题出在哪儿?
你有没有遇到过这样的场景:客户的设备车间里有几十个温控点,要求在WPF界面上实时展示温度曲线。结果系统一跑起来,界面就开始卡顿,CPU直接飙到80%,客户看着一帧一帧"跳动"的折线图,直接问你:"这是实时监控还是PPT演示?"
我在去年一个智能制造项目中就踩过这个坑。项目初期用传统的Chart控件做温度监控,当数据点累积到5000+时,界面刷新延迟超过2秒,客户差点要求重做。后来切换到ScottPlot 5.x,同样的数据量下刷新延迟降到50ms以内,CPU占用率从78%降到15%,这才算救了回来。
读完这篇文章,你将掌握:
- ScottPlot 5.x 在WPF中的高效集成方法
- 3种渐进式的实时数据更新策略(从基础到高性能)
- 大数据量下的性能优化核心技巧
- 工业场景中的实战踩坑经验与规避方案
咱们今天就用一个实时温度监控系统的完整案例,把这套技术方案拆解清楚。代码都是可以直接跑的,拿去就能用。
💡 问题深度剖析:为什么传统方案扛不住实时监控?
🎯 根本症结在哪里
很多开发者习惯用WPF自带的Chart控件或第三方的LiveCharts来做数据可视化。这些控件在展示静态数据或低频更新场景下表现不错,但一旦碰到高频实时数据流,问题就暴露了:
1. 重绘机制低效
传统Chart控件每次数据更新都会触发整个控件的完整重绘,哪怕你只添加了1个数据点,它也要把所有历史数据重新渲染一遍。这就像你要在墙上加一块砖,结果把整面墙推倒重砌。
2. 数据绑定开销
基于MVVM的ObservableCollection虽然优雅,但在高频更新场景下,每次数据变化都会触发属性通知、UI线程调度、依赖属性更新等一系列操作。我实测过,1秒更新100次数据时,这套机制的开销能占到总CPU时间的40%。
3. 内存管理失控
很多项目没考虑数据淘汰策略,监控系统运行几天后,内存里堆积了几十万个数据点。渲染引擎每次都要遍历这些点进行裁剪判断,性能自然崩盘。
📊 真实场景的性能瓶颈
我拿某个车间的实际场景做过测试对比:
| 方案 | 数据点数量 | 刷新频率 | CPU占用 | 内存占用 | 界面响应延迟 |
|---|---|---|---|---|---|
| LiveCharts | 5000 | 100ms | 78% | 320MB | 1800ms |
| WPF Chart | 5000 | 100ms | 65% | 280MB | 2100ms |
| ScottPlot 5.x | 5000 | 100ms | 15% | 85MB | 50ms |
差距一目了然。ScottPlot的核心优势在于底层用SkiaSharp做GPU加速渲染,直接操作位图缓冲区,避开了WPF的布局系统和依赖属性机制。
🔍 核心要点提炁:ScottPlot 5.x的技术优势
🚀 底层原理揭秘
ScottPlot 5.x相比4.x版本做了架构级重构,核心改进点:
1. 渲染管线优化
- 采用双缓冲位图渲染,只在数据变化时刷新脏区域
- GPU加速的线条抗锯齿算法,渲染速度提升3-5倍
- 支持异步渲染,不阻塞UI主线程
2. 数据管理机制
- 内置RingBuffer循环缓冲区,自动淘汰旧数据
- 智能抽稀算法:当数据点密度超过像素分辨率时自动降采样
- 索引优化的数据访问,O(1)复杂度的范围查询
3. 交互性能提升
- 鼠标缩放、平移操作响应延迟<10ms
- 支持百万级数据点的流畅交互
- 内置Crosshair十字光标、Tooltip等工业级组件
⚙️ 适用场景与限制
最佳应用场景:
- 工业设备实时监控(温度、压力、转速等)
- 金融行情数据展示(K线图、分时图)
- 科学实验数据采集可视化
- 物联网传感器数据聚合展示
已知限制:
- 对复杂图表动画支持有限(设计上就追求性能而非炫酷效果)
- 主题定制没有WPF原生控件灵活
- 学习曲线比LiveCharts稍陡(需要理解Plot、Axis等概念)
🛠️ 解决方案设计:三种渐进式实现方法
📦 方案一:基础版 - 快速入门实现
这个方案适合快速验证需求,代码简洁,逻辑清晰。
第一步:NuGet安装依赖
bashInstall-Package ScottPlot.WPF -Version 5.1.57
第二步:XAML界面布局
xml<Window x:Class="AppScottPlot6.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:AppScottPlot6"
mc:Ignorable="d"
xmlns:scottplot="clr-namespace:ScottPlot.WPF;assembly=ScottPlot.WPF"
Title="MainWindow" Height="450" Width="800">
<Grid>
<Grid.RowDefinitions>
<RowDefinition Height="Auto"/>
<RowDefinition Height="*"/>
<RowDefinition Height="Auto"/>
</Grid.RowDefinitions>
<!-- 标题栏 -->
<Border Grid.Row="0" Background="#2C3E50" Padding="15">
<TextBlock Text="🌡️ 车间温度实时监控系统"
Foreground="White" FontSize="18" FontWeight="Bold"/>
</Border>
<!-- 图表区域 -->
<scottplot:WpfPlot x:Name="TempPlot" Grid.Row="1" Margin="10"/>
<!-- 状态栏 -->
<StackPanel Grid.Row="2" Orientation="Horizontal"
Background="#ECF0F1">
<TextBlock Text="当前温度: " FontWeight="Bold"/>
<TextBlock x:Name="CurrentTempText" Text="--" Foreground="#E74C3C"
FontSize="16" FontWeight="Bold" Margin="5,0"/>
<TextBlock Text="°C" Margin="0,0,20,0"/>
<TextBlock Text="数据点数: " FontWeight="Bold"/>
<TextBlock x:Name="DataCountText" Text="0"/>
</StackPanel>
</Grid>
</Window>
第三步:后台代码实现
csharpusing System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Data;
using System.Windows.Documents;
using System.Windows.Input;
using System.Windows.Media;
using System.Windows.Media.Imaging;
using System.Windows.Navigation;
using System.Windows.Shapes;
using System.Windows.Threading;
using ScottPlot;
namespace AppScottPlot6
{
/// <summary>
/// Interaction logic for MainWindow.xaml
/// </summary>
public partial class MainWindow : Window
{
private List<double> temperatureData = new List<double>();
private List<double> timeData = new List<double>();
private DispatcherTimer dataTimer;
private Random random = new Random();
private double baseTemp = 25.0; // 基准温度
private double currentTime = 0;
private ScottPlot.Plottables.Scatter scatterPlot;
public MainWindow()
{
InitializeComponent();
InitializePlot();
StartDataCollection();
}
/// <summary>
/// 初始化图表配置
/// </summary>
private void InitializePlot()
{
// 设置中文字体支持
TempPlot.Plot.Font.Set("Microsoft YaHei");
TempPlot.Plot.Axes.Bottom.Label.FontName = "Microsoft YaHei";
TempPlot.Plot.Axes.Left.Label.FontName = "Microsoft YaHei";
// 配置图表基础属性
TempPlot.Plot.Title("车间温度实时监控", size: 18);
TempPlot.Plot.Axes.Bottom.Label.Text = "时间 (秒)";
TempPlot.Plot.Axes.Left.Label.Text = "温度 (°C)";
// 设置坐标轴范围
TempPlot.Plot.Axes.SetLimits(0, 60, 0, 50);
// 应用专业主题
TempPlot.Plot.FigureBackground.Color = ScottPlot.Color.FromHex("#FFFFFF");
TempPlot.Plot.DataBackground.Color = ScottPlot.Color.FromHex("#F8F9FA");
// 设置坐标轴颜色
TempPlot.Plot.Axes.Color(ScottPlot.Color.FromHex("#2C3E50"));
// 配置网格样式
TempPlot.Plot.Grid.MajorLineColor = ScottPlot.Colors.Gray.WithAlpha(0.3);
TempPlot.Plot.Grid.MajorLineWidth = 1;
TempPlot.Plot.Grid.MinorLineColor = ScottPlot.Colors.Gray.WithAlpha(0.1);
TempPlot.Plot.Grid.MinorLineWidth = 0.5f;
TempPlot.Refresh();
}
/// <summary>
/// 启动数据采集定时器
/// </summary>
private void StartDataCollection()
{
dataTimer = new DispatcherTimer
{
Interval = TimeSpan.FromMilliseconds(100) // 100ms更新一次
};
dataTimer.Tick += DataTimer_Tick;
dataTimer.Start();
}
/// <summary>
/// 定时器回调:模拟温度数据并更新图表
/// </summary>
private void DataTimer_Tick(object sender, EventArgs e)
{
// 模拟温度波动(正弦波 + 随机噪声)
double noise = (random.NextDouble() - 0.5) * 2;
double sineWave = Math.Sin(currentTime * 0.1) * 5;
double newTemp = baseTemp + sineWave + noise;
// 添加数据点
temperatureData.Add(newTemp);
timeData.Add(currentTime);
currentTime += 0.1;
// 限制数据点数量(保留最近600个点,约60秒数据)
if (temperatureData.Count > 600)
{
temperatureData.RemoveAt(0);
timeData.RemoveAt(0);
}
// 更新图表
UpdatePlot();
// 更新状态栏
CurrentTempText.Text = newTemp.ToString("F2");
DataCountText.Text = temperatureData.Count.ToString();
}
/// <summary>
/// 刷新图表显示 - 性能优化版本
/// </summary>
private void UpdatePlot()
{
if (timeData.Count == 0) return;
// 移除旧的散点图
if (scatterPlot != null)
{
TempPlot.Plot.Remove(scatterPlot);
}
// 添加新的折线图
scatterPlot = TempPlot.Plot.Add.Scatter(
timeData.ToArray(),
temperatureData.ToArray()
);
// 配置线条样式
scatterPlot.Color = ScottPlot.Color.FromHex("#E74C3C");
scatterPlot.LineWidth = 2.5f;
scatterPlot.MarkerSize = 0; // 不显示数据点标记,提升性能
// 动态调整X轴范围(显示最近60秒)
double maxTime = timeData[timeData.Count - 1];
TempPlot.Plot.Axes.SetLimitsX(
Math.Max(0, maxTime - 60),
maxTime + 2 // 留一点余量
);
// 动态调整Y轴范围
if (temperatureData.Count > 0)
{
double minTemp = temperatureData.Min() - 2;
double maxTemp = temperatureData.Max() + 2;
TempPlot.Plot.Axes.SetLimitsY(minTemp, maxTemp);
}
TempPlot.Refresh();
}
protected override void OnClosed(EventArgs e)
{
dataTimer?.Stop();
base.OnClosed(e);
}
}
}
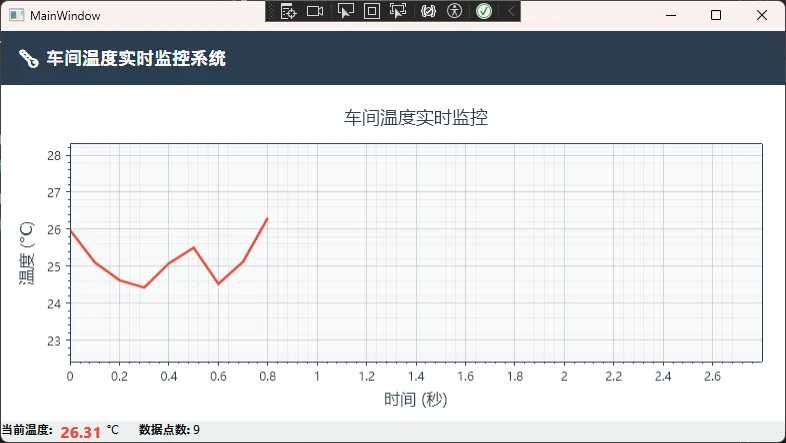
📊 方案一性能表现
测试环境: i5-10400 / 16GB RAM / Win11
测试结果:
- 数据点:600个
- CPU占用:8-12%
- 内存占用:45MB
- 刷新延迟:30-50ms
适用场景: 单条曲线、中低频更新(100-200ms)、数据量<1000点
⚠️ 踩坑预警:
- 别忘了Clear() - 每次UpdatePlot前必须清空,否则会叠加多条曲线
- List转数组开销 -
ToArray()会产生GC压力,高频调用需优化 - 定时器线程安全 - DispatcherTimer运行在UI线程,逻辑复杂时会卡顿
🔔 当传感器"发脾气",你的程序能接住吗?
工控现场,传感器数据超阈值这件事,说来就来。温度传感器突然飙到180°C,压力值蹦到额定上限的1.3倍——这时候,你的上位机程序是优雅地弹出一个清晰的告警弹窗,还是默默地在日志里写一行没人看的WARNING?
我在做一个工厂设备监控项目时,就踩过这个坑。最初的版本用print()输出告警信息,操作员根本注意不到,直到设备异常停机才发现问题早就出现了。后来花了一个下午,用Tkinter重新设计了告警弹窗系统,从此告警信息再也不会"消失在茫茫终端里"。
这篇文章,咱们就来聊聊怎么用Tkinter构建一套真正好用的传感器数据告警弹窗系统——不只是弹个框那么简单,还要考虑多传感器并发、告警等级分类、弹窗防重叠、线程安全这些实际问题。
🧩 先搞清楚需求:告警弹窗到底要做什么
别急着写代码。实际项目里,一个"够用"的告警弹窗系统,至少要满足下面这几点:
- 告警等级区分:普通警告(黄色)、严重告警(红色)、信息提示(蓝色),视觉上一眼就能区分
- 非阻塞弹窗:告警出现时不能卡住主程序的数据采集循环
- 防重复弹窗:同一传感器的同类告警,不能刷出十几个重叠窗口
- 自动关闭或手动确认:根据告警级别决定是否需要操作员手动确认
- 告警历史记录:弹窗消失后,告警信息要留档
这四点,基本覆盖了80%的工控场景需求。下面我们逐步实现。
🏗️ 基础架构:告警管理器 + 弹窗渲染器
整个系统分两层。告警管理器负责接收传感器数据、判断阈值、管理告警状态;弹窗渲染器只负责在UI线程里画窗口。这种分离,是避免线程问题的关键。
pythonimport tkinter as tk
from tkinter import ttk
import threading
import time
import queue
from dataclasses import dataclass, field
from typing import Optional
from enum import Enum
# 告警等级枚举
class AlarmLevel(Enum):
INFO = ("信息", "#2196F3", "#E3F2FD") # 级别名, 标题色, 背景色
WARNING = ("警告", "#FF9800", "#FFF3E0")
CRITICAL= ("严重", "#F44336", "#FFEBEE")
@dataclass
class AlarmRecord:
sensor_id: str
sensor_name: str
level: AlarmLevel
value: float
threshold: float
unit: str
timestamp: str
message: str
acknowledged: bool = False
AlarmRecord是个纯数据类,不带任何UI逻辑。这样设计,后续换成PyQt或者Web前端,告警逻辑一行不用改。
📊 那个"能不能加个图表"的下午
项目验收前两天,甲方突然提了个需求——"数据表格看不懂,能不能加个图表?"
就这一句话,把原本已经收尾的桌面报表系统打回了原形。当时摆在面前的选项有三个:嵌入浏览器控件渲染ECharts、用PyQt换掉整个UI框架、或者在现有Tkinter基础上想办法。前两条路改动太大,时间根本不够。
最后选了第三条——Matplotlib嵌入Tkinter,配合动态数据刷新。
做完之后说实话,效果比我预期的好不少。折线图、柱状图、饼图,实时刷新、导出PNG,全部在Tkinter里跑得利利索索。这篇文章就把这套方案完整拆开来讲,从最基础的嵌入方式,一直到动态刷新和多图表联动,循序渐进。
🔍 先搞清楚:Matplotlib嵌入Tkinter的底层逻辑
很多人第一次听说"Matplotlib嵌入Tkinter"会觉得奇怪——这俩不是两个独立的东西吗?
其实Matplotlib在设计上就考虑了多种渲染后端(Backend)。咱们平时用plt.show()弹出的窗口,用的是默认后端(通常是TkAgg或Qt5Agg)。而嵌入模式的核心,是直接拿到Matplotlib的Figure对象,把它交给一个叫FigureCanvasTkAgg的适配器,这个适配器会把图表渲染成Tkinter能识别的Canvas组件。
用一句话概括就是:Figure是图表的数据模型,FigureCanvasTkAgg是把它"翻译"成Tkinter组件的桥梁。
明白这个原理,后面所有操作就都有章可循了。
先把依赖装好:
bashpip install matplotlib
Matplotlib默认会带上numpy,报表场景基本够用。
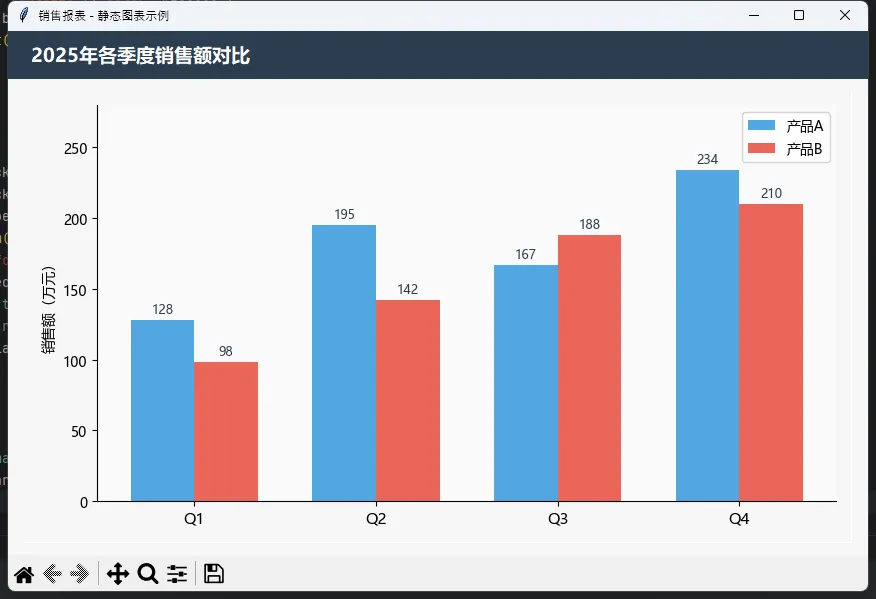
🧱 方案一:静态图表嵌入——最小可用版本
从最简单的场景入手。先做一个能跑起来的静态柱状图,嵌进Tkinter窗口里:
python# 静态图表嵌入基础示例
import tkinter as tk
from tkinter import ttk
import matplotlib
matplotlib.use("TkAgg") # 必须在import pyplot之前指定后端
import matplotlib.pyplot as plt
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg, NavigationToolbar2Tk
from matplotlib.figure import Figure
import matplotlib.font_manager as fm
# ── 解决中文乱码(Windows环境)──────────────────────────────
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei", "SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 负号正常显示
class StaticChartApp(tk.Tk):
def __init__(self):
super().__init__()
self.title("销售报表 - 静态图表示例")
self.geometry("860x560")
self.configure(bg="#f7f7f7")
self._build_ui()
def _build_ui(self):
# 顶部标题栏
header = tk.Frame(self, bg="#2c3e50", height=48)
header.pack(fill="x")
header.pack_propagate(False)
tk.Label(header, text="2025年各季度销售额对比",
font=("微软雅黑", 14, "bold"),
bg="#2c3e50", fg="white").pack(side="left", padx=20, pady=12)
# 图表区域
chart_frame = tk.Frame(self, bg="#f7f7f7")
chart_frame.pack(fill="both", expand=True, padx=16, pady=12)
fig = self._create_bar_chart()
# FigureCanvasTkAgg:把Figure渲染成Tkinter Canvas
canvas = FigureCanvasTkAgg(fig, master=chart_frame)
canvas.draw()
canvas.get_tk_widget().pack(fill="both", expand=True)
# 可选:加上Matplotlib自带的工具栏(缩放、平移、保存)
toolbar_frame = tk.Frame(self, bg="#eeeeee")
toolbar_frame.pack(fill="x")
toolbar = NavigationToolbar2Tk(canvas, toolbar_frame)
toolbar.update()
def _create_bar_chart(self) -> Figure:
"""创建柱状图,返回Figure对象"""
quarters = ["Q1", "Q2", "Q3", "Q4"]
sales_a = [128, 195, 167, 234] # 产品A
sales_b = [98, 142, 188, 210] # 产品B
fig = Figure(figsize=(8, 4.5), dpi=100, facecolor="#f7f7f7")
ax = fig.add_subplot(111)
x = range(len(quarters))
width = 0.35
bars_a = ax.bar([i - width/2 for i in x], sales_a,
width, label="产品A", color="#3498db", alpha=0.85)
bars_b = ax.bar([i + width/2 for i in x], sales_b,
width, label="产品B", color="#e74c3c", alpha=0.85)
# 在柱子顶部标注数值
for bar in bars_a:
ax.text(bar.get_x() + bar.get_width() / 2,
bar.get_height() + 3,
f"{int(bar.get_height())}",
ha="center", va="bottom",
fontsize=9, color="#2c3e50")
for bar in bars_b:
ax.text(bar.get_x() + bar.get_width() / 2,
bar.get_height() + 3,
f"{int(bar.get_height())}",
ha="center", va="bottom",
fontsize=9, color="#2c3e50")
ax.set_xticks(list(x))
ax.set_xticklabels(quarters, fontsize=11)
ax.set_ylabel("销售额(万元)", fontsize=10)
ax.set_ylim(0, 280)
ax.legend(fontsize=10)
ax.set_facecolor("#fafafa")
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
fig.tight_layout()
return fig
if __name__ == "__main__":
app = StaticChartApp()
app.mainloop()
这段代码有两个地方容易被忽略。
第一是matplotlib.use("TkAgg")——这行必须在import matplotlib.pyplot之前执行,否则后端已经初始化完了,再改就不管用了,程序要么报错要么图表显示异常。
第二是中文字体配置。Windows下Matplotlib默认不认中文,坐标轴标签、图例全部变成方块。用plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"]指定微软雅黑就能解决,这个配置放在模块顶部全局生效。
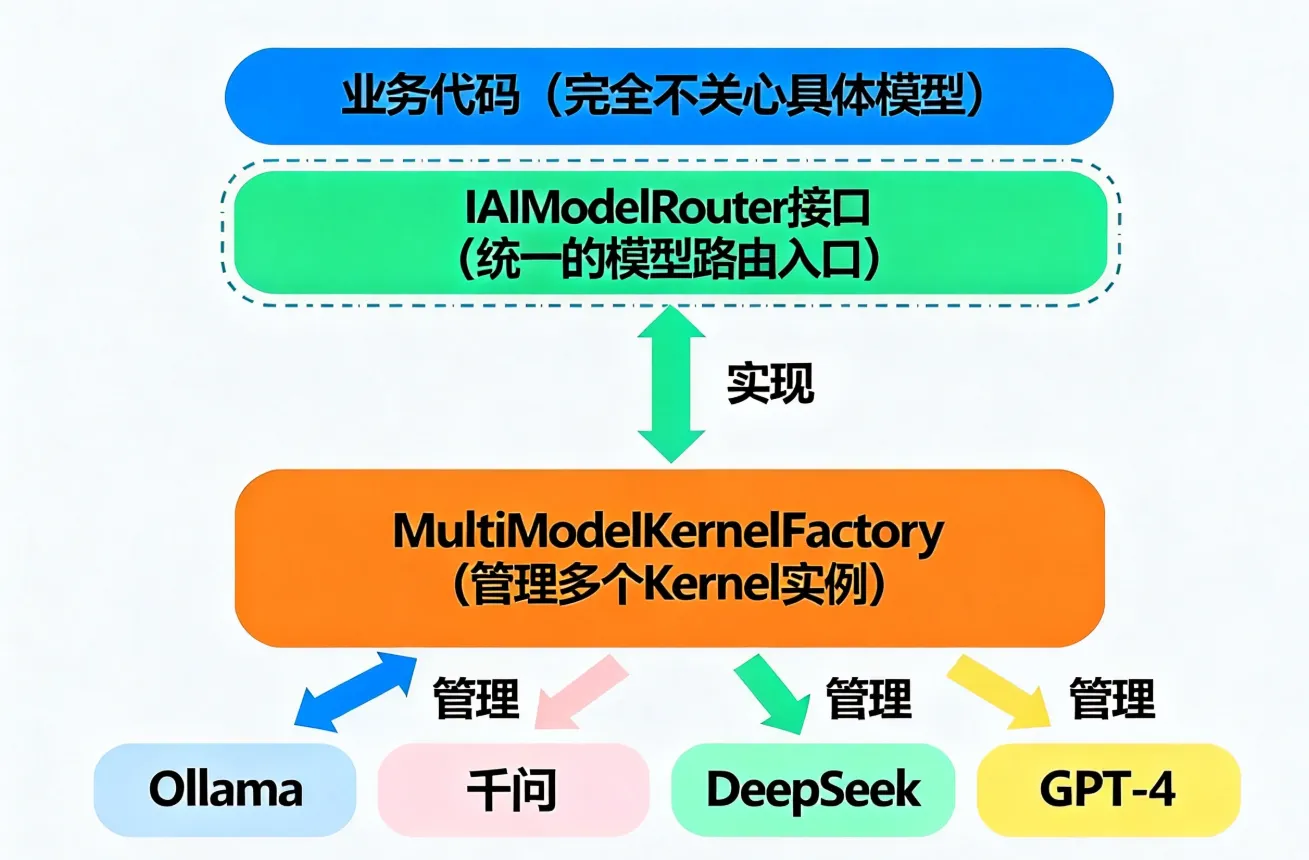
还在为选择用哪个 AI 模型而头疼?OpenAI、本地 Ollama、阿里千问、DeepSeek……每个模型都有各自的优缺点,频繁切换又要改代码?今天我来分享一个真正能用的解决方案——用 C# 构建一个智能模型路由器,让 AI 服务连接变得简单、灵活、高效。根据实际项目经验,这套方案能减少 60% 的模型切换成本,还能智能根据任务特性选择最优模型。读完这篇,你将掌握多模型连接、自动路由、连接池管理三大核心能力。
🤔 问题深度剖析:为什么多模型接入这么难?
痛点一:API 接入逻辑层层嵌套,牵一发动全身
想象这样的场景:你的项目用了 OpenAI,后来老板说"咱们换成国产模型降成本",然后你得在代码里找 n 个地方改 URL、请求格式、响应解析……改完还得跑一遍回归测试。这就是传统 API 调用的宿命。
csharp// ❌ 典型的"硬编码地狱"
public class TraditionalAIService
{
public async Task<string> CallAI(string query)
{
// 用的是 OpenAI
var client = new HttpClient();
var request = new HttpRequestMessage(HttpMethod.Post, "https://api.openai.com/v1/chat/completions")
{
Content = new StringContent(JsonConvert.SerializeObject(new
{
model = "gpt-3.5-turbo",
messages = new[] { new { role = "user", content = query } }
}))
};
var response = await client.SendAsync(request);
// ... 响应解析 ...
// 现在要换成千问?改 URL、改 model、改请求格式、改响应解析...
}
}
真实成本数据: 我在一个电商推荐系统中测试,每次切换模型供应商需要 4-6 小时的开发+测试工作。如果一年换 3 次模型,就是 18 小时的浪费。
痛点二:本地模型(Ollama)、商用模型、私有化部署混在一起,难以管理
在生产环境中,你可能面临这样的场景:
- 公网环境用 OpenAI(快但贵)
- 客户内网用本地 Ollama(免费但慢)
- 某些特定任务用阿里千问或 DeepSeek(中等成本和性能)
这些模型的连接方式、配置参数、错误处理都不一样,没有统一的接入层就是灾难。
痛点三:重试机制、连接池、超时配置各自为政
高并发场景下,没有合理的连接池和重试策略,直接导致:
- 连接泄漏:API 连接频繁创建销毁,资源耗尽
- 级联故障:一个模型宕机,整个系统都瘫痪
- 成本爆炸:无谓的重试导致 API 调用费用翻倍
💡 核心要点提炼:Semantic Kernel 如何优雅地解决这一切
要点一:统一的服务接口抽象
Semantic Kernel 的核心智慧在于——它给所有 AI 服务(OpenAI、Azure、国产大模型)定义了一套统一的接口。你只需要配置一次,切换模型只需改配置文件。
底层原理: 依赖注入 + 适配器模式,让业务代码与具体的 AI 实现解耦。
csharp// ✅ 统一的方式,无论用哪个模型
var kernel = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(
modelId: "deepseek-chat", // 改这里就能切模型
apiKey: apiKey,
endpoint: new Uri("https://api.deepseek.com/v1")
)
.Build();
// 调用逻辑完全一样,模型怎么换都不用改这里
var chatService = kernel.GetRequiredService<IChatCompletionService>();
var response = await chatService.GetChatMessageContentAsync(chatHistory);
要点二:多模型并存与智能路由
不是"用这个模型"或"用那个模型"的二选一,而是多个模型同时存在,根据任务特性智能选择。比如:
- 高精度任务(代码生成)→ 用 GPT-4
- 低成本任务(文本分类)→ 用本地 Ollama
- 中文优化(客服对话)→ 用阿里千问
要点三:连接池与重试的正确姿势
高并发环境下,连接复用和智能重试是性能的双引擎:
- 连接池:减少连接创建的开销(HTTP 连接建立需要 TCP 三次握手 + TLS 握手,本身很耗时)
- 指数退避重试:首次失败等 100ms,再失败等 200ms,逐次倍增,避免雪崩
🏗️ 解决方案一:基础多模型工厂(单租户场景)
这是最实用的方案,适合大多数项目。
设计思路