
🤔 你真的用对 Lambda 了吗?
在日常 C# 开发中,Lambda 表达式几乎是使用频率最高的语法特性之一。list.Where(x => x.Age > 18)、Task.Run(() => DoWork())、button.Click += (s, e) => Handle()——这些写法随手就来,顺畅得像呼吸一样自然。
但正因为太顺手,很多开发者从来没有停下来想过:Lambda 背后编译器到底做了什么?闭包捕获变量的时机是什么?匿名方法和 Lambda 有什么本质区别? 这些问题在 Code Review 里很少被追问,但在生产环境里,它们以内存泄漏、逻辑错误、性能劣化的形式悄悄埋下隐患。
我在多个中大型项目中见过这样的场景:一段看似简洁的 Lambda 循环,因为闭包变量捕获时机的误解,导致所有回调执行时拿到的是同一个"最终值",排查了半天才定位到根因。
读完本文,你将掌握:
- Lambda 与匿名方法的编译器处理机制
- 闭包的变量捕获原理与经典陷阱规避
- 3 个渐进式实战方案,覆盖性能优化与架构设计
🔍 问题深度剖析:Lambda 不只是"简化写法"
匿名方法是 Lambda 的前身,但不完全等价
C# 2.0 引入了匿名方法(Anonymous Method),C# 3.0 引入了 Lambda 表达式。很多人认为 Lambda 只是匿名方法的语法糖,这个说法大体正确,但存在一个关键差异。
csharp// C# 2.0 匿名方法写法
Func<int, bool> isEven_old = delegate(int x) { return x % 2 == 0; };
// C# 3.0 Lambda 表达式写法
Func<int, bool> isEven_new = x => x % 2 == 0;
// 两者编译后几乎等价,但匿名方法有一个独特能力:
// 可以忽略参数列表(Lambda 不行)
Action<int, string> ignore = delegate { Console.WriteLine("我不在乎参数"); };
// 等价于:(int _, string _) => Console.WriteLine(...)
// Lambda 必须声明参数,即使不用
这个细节在事件处理中很实用——当你只想订阅事件但不关心参数时,delegate { } 比 (s, e) => { } 更简洁,语义也更明确。
编译器对 Lambda 做了什么?
这才是理解一切的基础。Lambda 表达式在编译时会被转换成以下两种形式之一,取决于它是否捕获了外部变量:
情况一:无捕获变量 → 静态方法
csharpvar numbers = new List<int> { 1, 2, 3, 4, 5 };
// 这个 Lambda 没有捕获任何外部变量
var evens = numbers.Where(x => x % 2 == 0);
编译器会将其优化为一个静态方法,甚至缓存为静态字段,整个程序生命周期只创建一次委托实例。性能最优,无额外内存分配。
情况二:有捕获变量 → 编译器生成闭包类
csharpint threshold = 10; // 外部变量
// 这个 Lambda 捕获了 threshold
var filtered = numbers.Where(x => x > threshold);
编译器会生成一个隐藏的闭包类(编译器命名类似 <>c__DisplayClass0_0),大致等价于:
csharp// 编译器自动生成的闭包类(伪代码)
private sealed class DisplayClass0_0
{
public int threshold; // 捕获的变量变成字段
internal bool FilterMethod(int x)
{
return x > this.threshold; // 通过字段访问
}
}
// 原代码等价于:
var closure = new DisplayClass0_0();
closure.threshold = threshold;
var filtered = numbers.Where(closure.FilterMethod);
关键认知:捕获的是变量本身(引用),不是变量的值的副本。这一点是所有闭包陷阱的根源。
上周有个做自动化的朋友找我抱怨:他们厂里的上位机软件,界面丑得像 2003 年的网吧管理系统,逻辑全堆在一个 Form 里,动不动就假死。他问我,C# 能不能做出像样的 SCADA 界面?我说,不仅能,还能做得很优雅。这篇文章,就把我的实战思路完整拆给你看。
🏭 先搞清楚,SCADA 到底要解决什么问题
SCADA(数据采集与监视控制系统)这个词听起来很唬人,但本质上,它干的事情就三件:采数据、看数据、管设备。
工业现场的开发者最头疼的,不是算法,是结构。你见过那种把所有逻辑全塞进 Form1.cs 的上位机代码吗?定时器回调里直接操 UI,报警判断和趋势绘图混在一起,改一个需求,整个文件都得翻。这玩意儿,维护起来真的是噩梦。
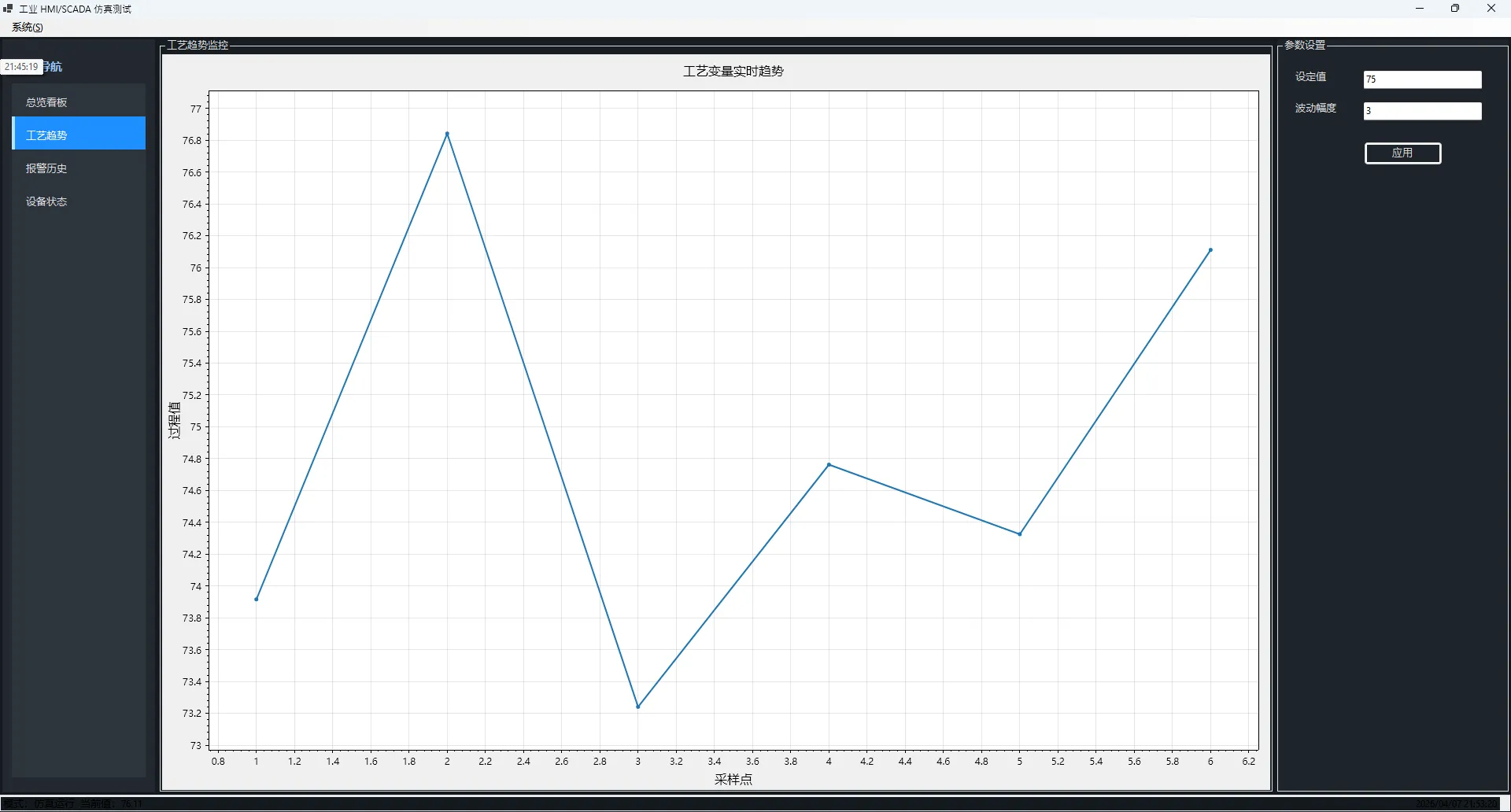
咱们今天要做的这个 Demo,麻雀虽小,五脏俱全——实时趋势、报警历史、设备状态、参数配置,四个模块,一套导航,外加一个仿真引擎驱动数据。
👨💻 看一下样式
🧱 架构先行:别急着写代码
很多人上来就拖控件、写事件,结果代码越写越乱。工业软件有个特点——模块多、状态复杂、需要长期维护。所以在动手之前,先把结构想清楚。
这个项目的核心思路是:单一 Form + 动态模块切换。
不是每个功能一个 Form,也不是 UserControl 堆叠,而是用一个 GroupBox 作为内容区,根据导航选择动态换入不同的控件。听起来简单,但细节里藏着不少门道。
布局上,用 TableLayoutPanel 三列分割:左侧导航、中间内容区、右侧参数面板。右侧面板只在"工艺趋势"模块下可见,其余模块直接把列宽收为 0,视觉上干净利落。
csharpprivate void SetRightPanelVisible(bool visible)
{
pnlRight.Visible = visible;
// 不是 Hide,而是直接把列宽归零——这样布局不会留白
tlpRoot.ColumnStyles[2].Width = visible ? RightPanelWidth : 0F;
}
这个小细节很多人会忽略。直接 Hide 控件,TableLayoutPanel 那一列还是会占位,界面会出现一块莫名其妙的空白。
生产环境某次 AI 调用莫名超时,排查了两小时,最终发现是 Temperature 参数配置异常导致响应时间暴增 300%。如果当时有完善的日志监控体系,这个问题五分钟就能定位。
在构建 Semantic Kernel 应用时,日志与监控往往是最容易被忽视的环节。代码跑通了、接口通了,然后就直接上线——这种操作在小项目里或许无伤大雅,但在生产环境中,一旦出现 AI 调用失败、Token 超支、响应延迟飙升等问题,没有监控就等于盲开飞机。
读完本文,你将掌握:
- ILogger 与 Semantic Kernel 的深度集成方式
- Serilog 结构化日志的实战配置
- Application Insights 遥测接入
- 性能分析工具的选用与使用技巧
- 一套可直接复用的完整日志监控系统模板
1️⃣ 问题深度剖析:没有监控的 AI 应用有多危险
🚨 三个典型痛点场景
痛点一:AI 调用失败后无迹可查
很多项目的错误处理长这样:
csharp// ❌ 典型的"吞掉异常"写法
try
{
var result = await kernel.InvokePromptAsync(prompt);
return result.ToString();
}
catch (Exception ex)
{
return "服务暂时不可用"; // 问题被掩盖,运维完全不知道
}
这种写法导致的后果是:用户反馈"AI 不好用",运维查不到任何错误信息,开发只能干瞪眼。
痛点二:Token 消耗失控
Semantic Kernel 每次调用都会消耗 Token,如果没有监控,以下情况很容易发生:
- ChatHistory 无限增长,单次请求 Token 超 8000
- 某个插件被频繁触发,一天消耗正常量的 10 倍
- 生产环境 Temperature=0.9(本该是开发配置),导致回复质量下降
痛点三:性能劣化无法感知
没有追踪时,你根本不知道:响应从 800ms 变成 3000ms 是从哪天开始的?是模型接口变慢了,还是某个插件计算耗时暴增?
2️⃣ 核心要点提炼:日志监控的底层逻辑
📐 分层监控模型
一个完整的 Semantic Kernel 监控体系,需要覆盖三层:
| 层级 | 监控内容 | 工具选型 |
|---|---|---|
| 应用层 | 业务逻辑、用户请求、对话历史 | ILogger + Serilog |
| 框架层 | SK 内核事件、函数调用、插件触发 | SK 内置事件钩子 |
| 基础设施层 | HTTP 请求、延迟、Token 用量 | Application Insights |
🔑 关键设计原则
- 结构化优于文本:
logger.LogInformation("Token: {TokenCount}", count)远比logger.LogInformation($"Token: {count}")好查询 - 上下文随调用链传递:每次 AI 调用应携带 TraceId,便于端到端追踪
- 性能数据必须量化:记录耗时、Token 数、重试次数,不能只记"成功/失败"
3️⃣ 解决方案设计
🛠️ 方案一:ILogger 基础集成(适合快速起步)
这是最轻量的方案,适合中小项目快速接入监控能力。
第一步:配置日志级别
json// appsettings.json
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.SemanticKernel": "Debug",
"AppAiAgent": "Debug"
}
}
}
💡 将
Microsoft.SemanticKernel设为Debug,SK 框架会自动输出函数调用、模型请求等详细信息。
第二步:封装带监控的 AI 服务
csharpusing Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Diagnostics;
public class MonitoredAIService
{
private readonly Kernel _kernel;
private readonly ILogger<MonitoredAIService> _logger;
public MonitoredAIService(Kernel kernel, ILogger<MonitoredAIService> logger)
{
_kernel = kernel;
_logger = logger;
}
public async Task<string> InvokeWithLoggingAsync(string prompt, string traceId = null)
{
// 生成追踪 ID,便于日志关联
traceId ??= Guid.NewGuid().ToString("N")[..8];
var sw = Stopwatch.StartNew();
_logger.LogInformation(
"[{TraceId}] AI 调用开始 | Prompt 长度: {PromptLength}",
traceId, prompt.Length);
try
{
var result = await _kernel.InvokePromptAsync(prompt, new KernelArguments(
new OpenAIPromptExecutionSettings
{
MaxTokens = 2000,
Temperature = 0.7
}));
sw.Stop();
var response = result.ToString();
// 记录成功调用的关键指标
_logger.LogInformation(
"[{TraceId}] AI 调用成功 | 耗时: {ElapsedMs}ms | 响应长度: {ResponseLength}",
traceId, sw.ElapsedMilliseconds, response?.Length ?? 0);
return response ?? string.Empty;
}
catch (HttpRequestException ex)
{
sw.Stop();
_logger.LogError(ex,
"[{TraceId}] 网络请求失败 | 耗时: {ElapsedMs}ms | 错误: {ErrorMessage}",
traceId, sw.ElapsedMilliseconds, ex.Message);
throw;
}
catch (Exception ex)
{
sw.Stop();
_logger.LogError(ex,
"[{TraceId}] AI 调用异常 | 耗时: {ElapsedMs}ms | 类型: {ExceptionType}",
traceId, sw.ElapsedMilliseconds, ex.GetType().Name);
throw;
}
}
}
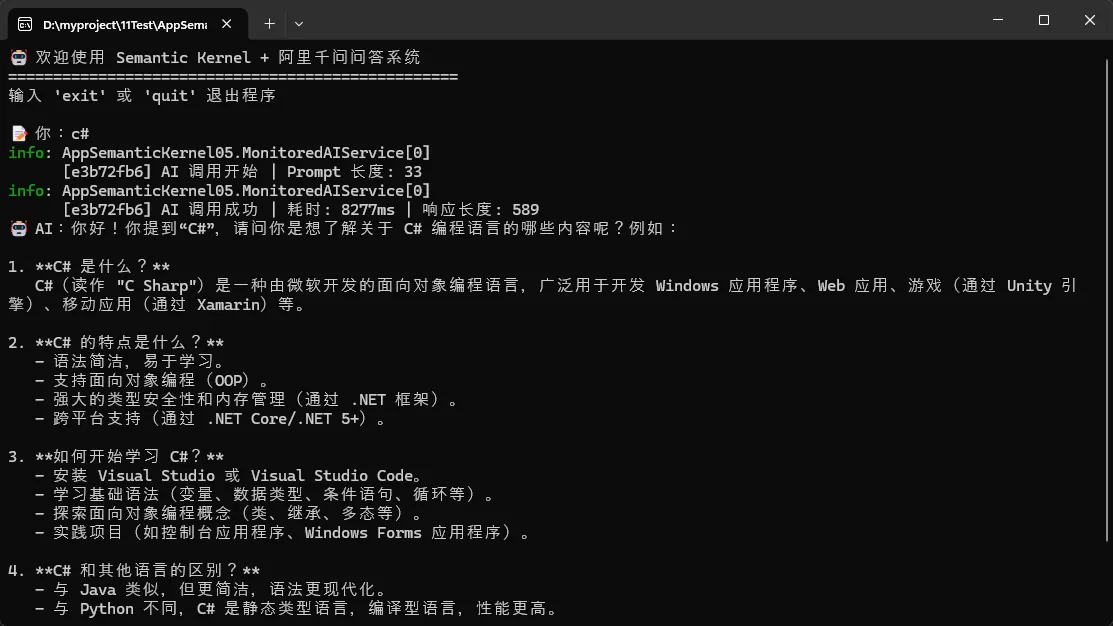
踩坑预警: 不要在日志里记录完整的 prompt 内容,特别是包含用户输入的场景——一方面是隐私风险,另一方面会让日志文件迅速膨胀。记录长度和关键标识即可。
项目越做越大,解决方案里的程序集越来越多,引用关系像一张乱麻——改一个底层库,上层十几个项目跟着报错;NuGet 包版本冲突让构建失败,排查半天才发现是某个间接依赖在作怪;发布时 DLL 文件一堆,不知道哪些是必要的,哪些是冗余的。
这些问题在 Winform 项目里尤为常见,因为桌面应用往往历史包袱重,多年积累下来的程序集管理问题会在某一天集中爆发。
读完本文,你将掌握:
- .NET 8 下 Winform 程序集的组织原则与分层策略
- NuGet 引用管理的最佳实践,彻底告别版本冲突
- 程序集加载机制与依赖注入的结合实践
- 可直接复用的项目结构模板与配置代码
🔍 问题深度剖析:引用混乱从何而来?
程序集膨胀的根源
在中大型 Winform 项目里,程序集管理混乱通常不是某一次决策失误造成的,而是长期"随手加引用"积累的结果。某个功能需要 JSON 序列化,就加了 Newtonsoft.Json;另一个模块需要日志,又加了 log4net;后来迁移到 .NET 6,顺手又引入了 Microsoft.Extensions.Logging——两套日志框架并存,谁也没人清理。
这种现象背后有两个核心问题:
其一,缺乏分层意识。 很多 Winform 项目只有一个主工程,所有逻辑——UI、业务、数据访问、工具类——全部堆在一起。这意味着每一个引用都是全局可见的,任何地方都可以直接 new 出数据库连接,引用关系没有任何约束。
其二,NuGet 的间接依赖问题被忽视。 当你引入包 A,包 A 依赖包 B 的 1.0 版本,而你另一个模块直接依赖包 B 的 2.0 版本,就会产生版本冲突。在 .NET Framework 时代这个问题通过 bindingRedirect 勉强解决,到了 .NET 8 的 SDK 风格项目,规则变了,很多老项目迁移时在这里栽跟头。
💡 核心要点提炼
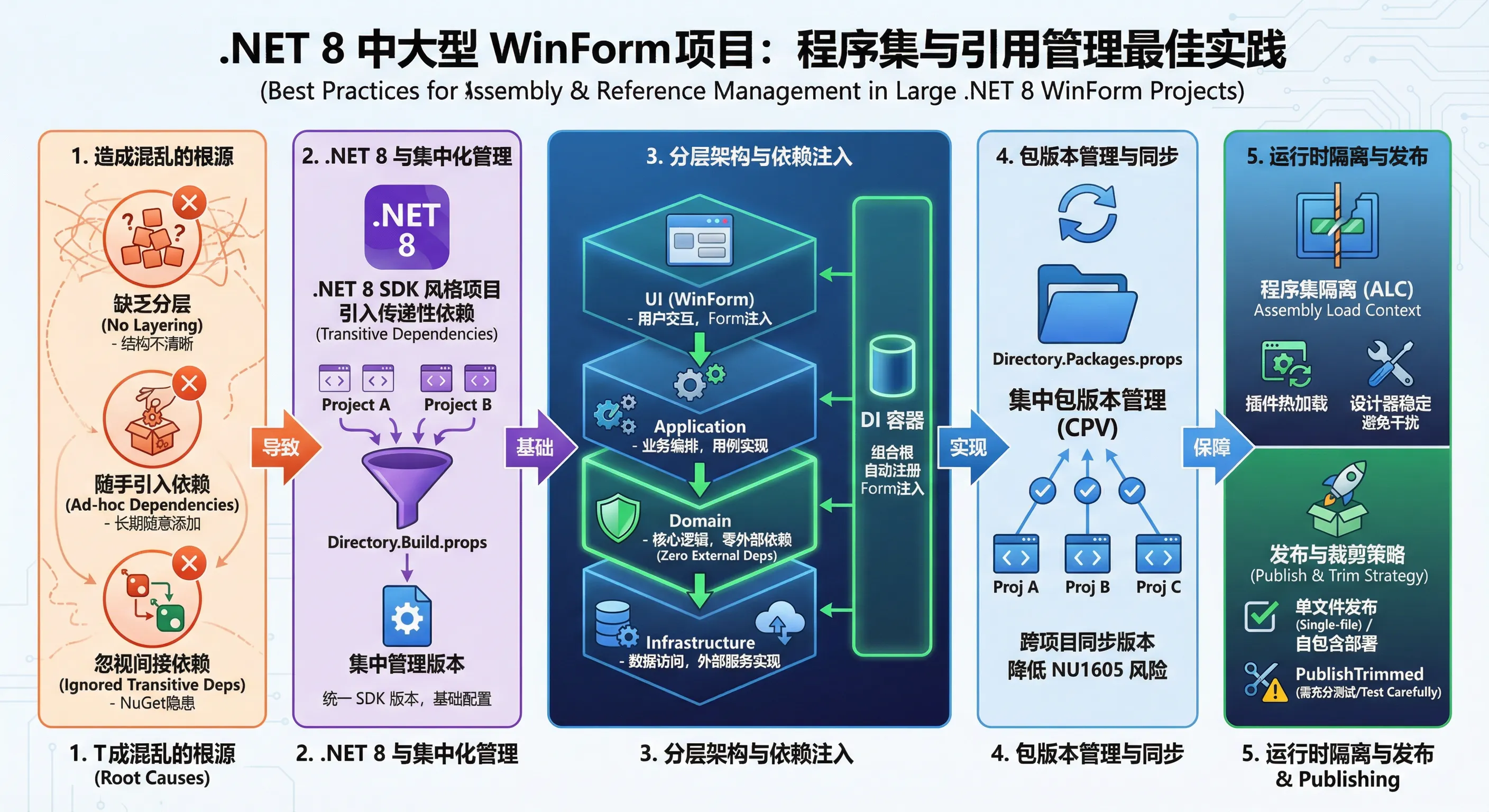
.NET 8 程序集加载机制变化
.NET 8 沿用了 .NET Core 的 AssemblyLoadContext(ALC)机制,与 .NET Framework 的 AppDomain 有本质区别。每个 ALC 都有独立的加载上下文,这意味着同一个程序集可以在不同上下文中以不同版本共存——这是插件化架构的基础,也是理解程序集隔离的关键。
对于普通 Winform 应用,默认的 AssemblyLoadContext.Default 足够使用,但如果你的应用需要支持插件热加载(比如模块化的工业软件),就必须为每个插件创建独立的 ALC,否则卸载插件时内存无法释放。
SDK 风格项目文件的优势
.NET 8 的 .csproj 文件采用 SDK 风格,相比老式项目文件简洁得多。一个关键特性是**传递性依赖(Transitive Dependencies)**的自动处理——你不需要在每个项目里都显式引用底层依赖,NuGet 会自动解析依赖树。
但这把双刃剑也带来了隐患:传递性依赖的版本可能不受你控制。解决方案是在解决方案根目录使用 Directory.Build.props 统一管理版本,这是 .NET 8 项目中最被低估的实践之一。
你有没有遇到过这种情况——项目跑了半年,突然要改个数据库地址,结果发现这个 IP 被硬编码在七八个文件里,改得头皮发麻?或者配置文件格式五花八门,JSON、YAML、INI 各自为政,每次读取都要写一堆重复代码?
咱们今天就来彻底解决这个问题。
🤔 配置管理,到底难在哪?
说实话,配置管理这件事,很多人觉得"不就是读个文件嘛",但真正在项目里栽过跟头的人才知道——坑深着呢。
我在一个工控项目里见过这样的代码:
pythonHOST = "192.168.1.100"
PORT = 5432
DB_NAME = "production_db"
硬编码直接写死在业务逻辑里。开发环境、测试环境、生产环境全用同一套,出了问题排查半天,最后发现只是个地址没改。这种"意大利面条式"的配置方式,在小项目里凑合,一旦规模上去,维护成本直线飙升。
更麻烦的是格式问题。老项目用 .ini,新模块喜欢 .yaml,前端同学提交了个 .json,偶尔还有人整个 .toml——每种格式都要单独写解析逻辑,代码冗余不说,还容易出错。
那有没有一种方案,能自动扫描目录、识别格式、统一加载,还带个可视化界面?
有。今天咱们就用 Python + Tkinter 从零撸一个出来。
🏗️ 整体设计思路
整个系统分两层:
底层是 ConfigLoader 核心类,负责扫描目录、按后缀匹配解析器、深度合并配置、提供点号路径访问。
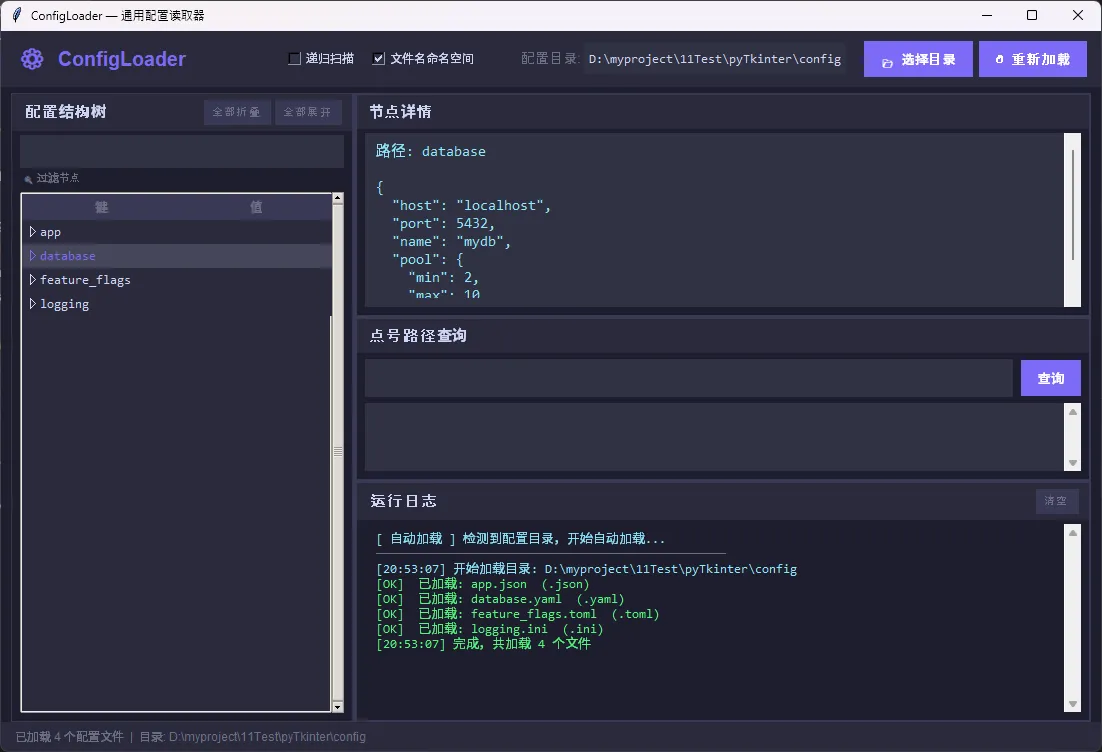
上层是 ConfigLoaderApp GUI 界面,基于 Tkinter 实现,包含配置树、节点详情、路径查询、运行日志四个功能区。
两层之间通过回调函数 log_callback 解耦——核心类完全不依赖 GUI,可以单独在命令行项目里使用。这个设计挺重要,别把业务逻辑和界面逻辑搅在一起。
运行效果
⚙️ 核心类:ConfigLoader
解析器注册表
python_PARSERS: Dict[str, str] = {
".json": "_parse_json",
".yaml": "_parse_yaml",
".yml": "_parse_yaml",
".toml": "_parse_toml",
".ini": "_parse_ini",
".cfg": "_parse_ini",
}
这是整个设计里我最喜欢的一个细节——用字典把文件后缀映射到方法名,扩展新格式只需要两步:注册后缀、实现解析方法。不用改任何已有逻辑,典型的开闭原则。
