
🔍 你是否也遇到过这些困境
做数据可视化的项目,选图表库这件事往往比写业务逻辑还让人头疼。用 GDI+ 手撸散点图?坐标轴、缩放、Tooltip 全得自己实现,一个功能完整的散点图没个两三天下不来。换 WPF?项目历史包袱太重,迁移成本根本不现实。
LiveCharts 2 是目前 .NET 生态里体验相当不错的图表库,支持 WPF、WinForms、MAUI、Blazor,底层渲染引擎统一,API 设计现代化。但官方文档对 WinForms 散点图的说明相当简略,很多细节——比如自定义点样式、动态数据更新、多系列差异化渲染——都得自己摸索。
读完这篇文章,你将掌握:
- LiveCharts 2 在 WinForms 中的正确集成姿势
- 散点图从基础到进阶的三个渐进式实现方案
- 动态数据刷新与性能优化的关键技巧
🧩 问题深度剖析:散点图为什么难做
散点图表面上看简单——不就是一堆点吗?但真正落地到工业数据监控、传感器数据分析、质量管控等场景时,麻烦就来了。
第一个坑:坐标轴精度控制。 传统控件的坐标轴往往是整数刻度,遇到浮点精度数据(比如 0.0023、0.9987 这类),刻度显示要么挤成一团,要么跨度太大丢失细节。
第二个坑:大数据量渲染卡顿。 在测试环境下,一次性渲染 5000 个点,使用 GDI+ 手绘方案平均帧率只有 4~6 FPS,界面几乎不可交互。LiveCharts 2 底层使用 SkiaSharp 渲染,同等数量级下帧率可维持在 30 FPS 以上(测试环境:i7-12700H,16GB RAM,.NET 6,Windows 11)。
第三个坑:多系列数据区分困难。 当同一张图上需要展示多组数据(比如不同批次、不同设备)时,颜色、形状、大小的差异化配置如果没有统一管理,代码很快变成"颜色硬编码大杂烩"。
这三个问题,下面三个方案会逐一解决。
📦 环境准备与包安装
开发环境: .NET 6 / .NET 8,Visual Studio 2022,WinForms 项目
通过 NuGet 安装以下包:
LiveChartsCore.SkiaSharpView.WinForms
或在包管理器控制台执行:
powershellInstall-Package LiveChartsCore.SkiaSharpView.WinForms
注意:LiveCharts 2 与 LiveCharts(v1)是完全不同的库,API 不兼容,不要装错。
🚀 方案一:基础散点图快速上手
这是最简单的起点,适合快速验证效果、做 Demo 原型。
步骤一:在 Form 中添加 CartesianChart 控件
LiveCharts 2 的 WinForms 控件不会自动出现在工具箱,需要手动在代码中实例化并添加到窗体。
csharpusing LiveChartsCore;
using LiveChartsCore.SkiaSharpView;
using LiveChartsCore.SkiaSharpView.WinForms;
namespace AppLiveChart06
{
public partial class Form1 : Form
{
private CartesianChart _chart;
public Form1()
{
InitializeComponent();
InitChart();
}
private void InitChart()
{
_chart = new CartesianChart
{
Dock = DockStyle.Fill
};
this.Controls.Add(_chart);
// 准备散点数据
var values = new List<LiveChartsCore.Defaults.ObservablePoint>
{
new(1.2, 3.4),
new(2.5, 1.8),
new(3.1, 4.7),
new(4.0, 2.2),
new(5.3, 5.0),
new(6.1, 3.9),
};
// 配置散点系列
_chart.Series = new ISeries[]
{
new ScatterSeries<LiveChartsCore.Defaults.ObservablePoint>
{
Values = values,
Name = "数据集 A",
}
};
}
}
}
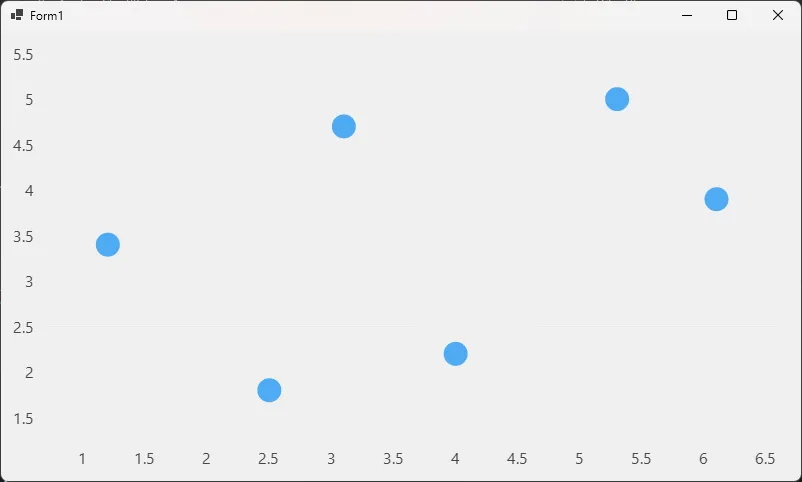
运行后就能看到一张基础散点图。ObservablePoint 是 LiveCharts 2 内置的二维坐标点类型,直接传入 X、Y 值即可,不需要额外的数据转换。
🧩 你的界面,真的"活着"吗?
做桌面应用的朋友,应该都踩过这个坑——点了一个按钮,整个窗口就像被人按了暂停键,鼠标转圈,标题栏显示"未响应"。用户那边已经开始骂人了,你这边还在纳闷:代码明明跑通了啊?
这不是代码逻辑的问题。这是事件循环的问题。
CustomTkinter 建立在 Tkinter 之上,而 Tkinter 的核心是一个单线程的事件循环——mainloop()。所有的界面渲染、用户交互、回调函数,全都挤在这一条"单行道"上跑。你往回调里塞一个耗时操作,整条道就堵死了。界面自然也就"卡死"了。
我在一个工业数据采集项目里,第一版代码就犯了这个错误:把串口读取的逻辑直接写在按钮回调里,结果采集一跑,界面冻住,客户以为程序崩了,直接拔电源。那次教训,让我把这套事件模型彻底研究透了。
这篇文章,我们就来把这个问题拆开来看,聊聊几个真正能用的设计模式。
🔍 先搞清楚:Tkinter 事件循环到底在干什么
mainloop() 本质上是一个无限循环,它不停地从事件队列里取事件、处理事件。鼠标点击是事件,键盘输入是事件,窗口重绘也是事件。
python# 伪代码,帮助理解 mainloop 的本质
while True:
event = event_queue.get()
dispatch(event) # 调用对应的回调函数
update_ui() # 更新界面
关键就在 dispatch(event) 这一步。回调函数是在主线程里同步执行的。你的回调跑多久,事件循环就被占多久。期间没有任何界面更新,没有任何用户输入响应——界面就"死"了。
这是 Tkinter 的设计,不是 Bug。理解这一点,后面的所有设计模式才有意义。
🚀 模式一:after() 方法——最被低估的武器
很多人不知道,Tkinter 自带一个非阻塞的定时调度机制:widget.after(ms, callback)。它的作用是:在指定毫秒后,把回调函数塞进事件队列,而不是立刻执行、阻塞当前流程。
这玩意儿特别适合处理"需要持续轮询"的场景,比如进度更新、状态监控。
pythonimport customtkinter as ctk
class ProgressApp(ctk.CTk):
def __init__(self):
super().__init__()
self.title("非阻塞进度示例")
self.geometry("400x200")
self.progress = ctk.CTkProgressBar(self)
self.progress.pack(pady=20, padx=20, fill="x")
self.progress.set(0)
self.label = ctk.CTkLabel(self, text="准备就绪")
self.label.pack()
self.btn = ctk.CTkButton(self, text="开始任务", command=self.start_task)
self.btn.pack(pady=10)
self._task_value = 0
self._running = False
def start_task(self):
if self._running:
return
self._running = True
self._task_value = 0
self.btn.configure(state="disabled")
self._run_step() # 启动分步执行
def _run_step(self):
"""每次只执行一小步,然后把下一步交还给事件循环"""
if self._task_value < 100:
self._task_value += 2
self.progress.set(self._task_value / 100)
self.label.configure(text=f"处理中... {self._task_value}%")
# 关键:50ms 后再执行下一步,期间事件循环可以正常工作
self.after(50, self._run_step)
else:
self.label.configure(text="完成!")
self.btn.configure(state="normal")
self._running = False
if __name__ == "__main__":
app = ProgressApp()
app.mainloop()
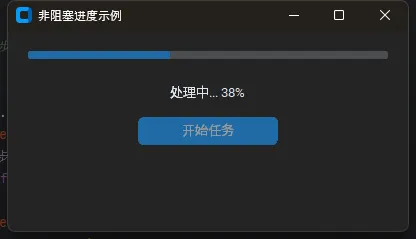
注意 _run_step 的设计——它每次只做一小块工作,然后用 after(50, self._run_step) 把控制权还给事件循环。界面始终是响应的,进度条也能实时更新。
适用场景:进度条动画、状态轮询、动画效果、周期性数据刷新。不适合真正的 CPU 密集型任务——那得用下面的方案。
写在前面:咱们做工业软件的,谁还没被那些丑到爆的监控界面折磨过?今天就来聊聊如何用C#打造一个让甲方爸爸都夸赞的实时数据可视化系统。
💀 那些年,我们踩过的界面"坑"
说起工业监控软件的界面...emmm,怎么说呢?
大多数时候是这样的:灰突突的背景,花花绿绿的按钮,还有那些让人眼花缭乱的数据表格。更要命的是——卡!顿!崩!溃!
我记得之前接手一个流量监控项目。客户很直接:"小张啊,你看这界面,员工都不愿意用。能不能搞得专业一点?"
专业一点?这可难倒我了。
直到遇见了ScottPlot...
🎯 为什么选择ScottPlot?三个字:真香!
性能表现让人意外
咱们先看数据:
- 传统Chart控件:1000个数据点卡成狗
- ScottPlot Signal:100万个数据点依然丝滑
这差距,简直是"五菱宏光"和"特斯拉"的区别。
API设计符合程序员直觉
csharp// 传统方式(想想都头疼)
chart.Series[0].Points.Clear();
foreach(var point in dataPoints) {
chart.Series[0].Points.AddXY(point.X, point.Y);
}
chart.Invalidate(); // 还要手动刷新...
// ScottPlot方式(一行搞定)
plot.Add.Signal(dataArray);
plot.Refresh(); // 就这么简单
看到没?这就是"人性化"设计的力量。
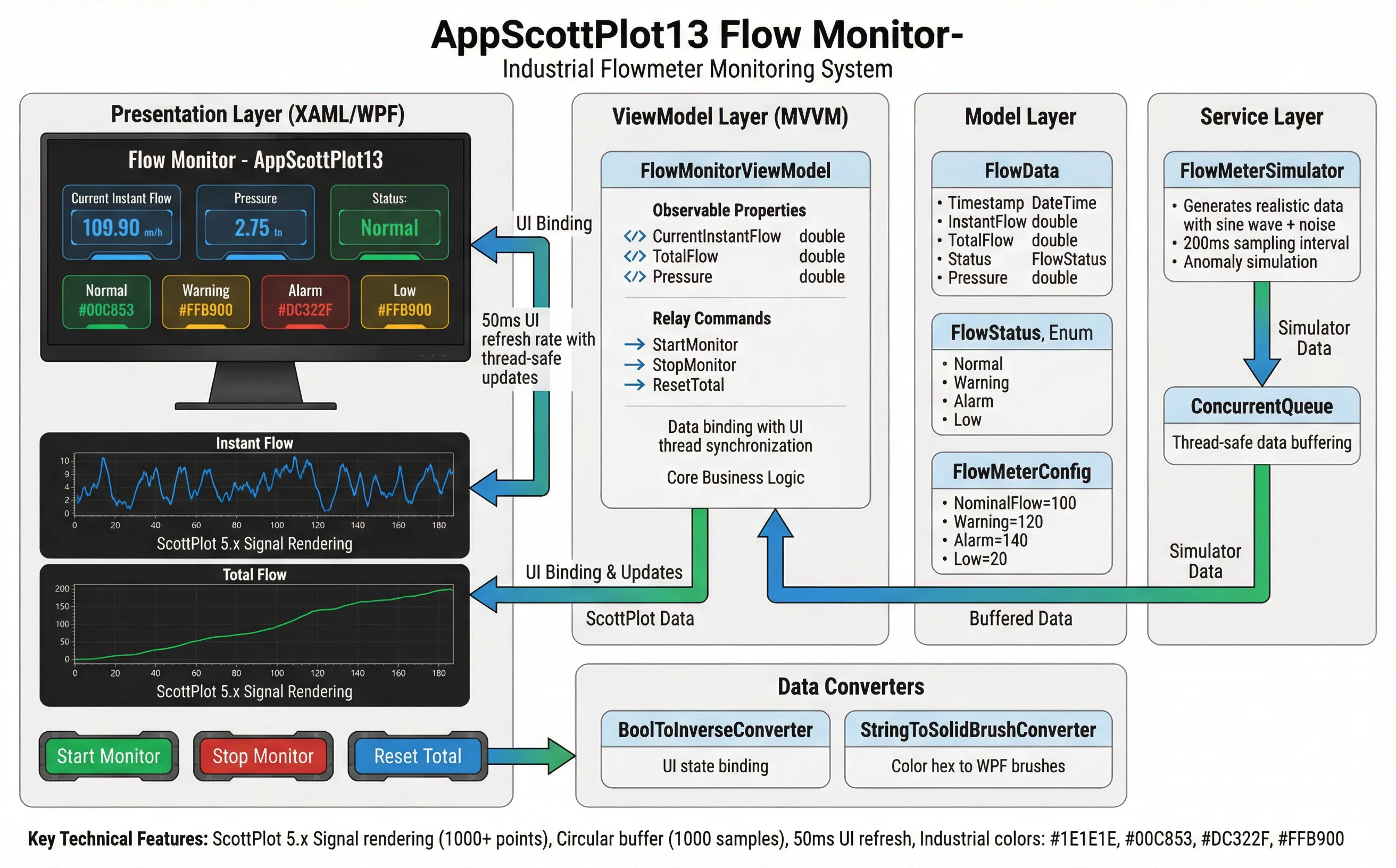
🏗️ 实战项目:流量计监控系统架构揭秘
核心设计思路
我们要搞的不是玩具,而是能上生产环境的"工业级"系统。
MVVM模式 + 实时数据流 + 高性能图表
这套组合拳,稳!
数据模型设计
csharppublic class FlowData
{
public DateTime Timestamp { get; set; }
public double InstantFlow { get; set; } // 瞬时流量
public double TotalFlow { get; set; } // 累计流量
public FlowStatus Status { get; set; } // 四级状态
public double Pressure { get; set; } // 管道压力
}
简单?对,就是要简单!复杂的业务逻辑交给服务层去处理。
状态管理的小心机
csharppublic enum FlowStatus
{
Normal, // ✅ 正常
Warning, // ⚠️ 警告
Alarm, // 🚨 报警
Low // ⬇️ 低流量
}
四个状态,对应四种颜色,对应四种处理策略。
工业现场就是这么直接。
在生产环境中,一个没有容错设计的 AI 服务就像在走钢丝——平时没问题,但一旦 API 超时或限流,整个链路就会崩掉。本文将带你系统掌握 SK 异常体系、Polly 重试、熔断器与优雅降级,最终实现一个可直接落地的健壮 AI 服务包装器。
🔥 为什么容错设计是 AI 应用的"生命线"?
在写完一个 AI 功能,本地跑通之后,很多开发者就直接上线了。但上线后往往遇到这样的场景:
- 凌晨三点,OpenAI/DeepSeek API 出现抖动,服务报错率飙升至 30%
- 高并发时段,触发 Rate Limit,大量请求直接抛异常
- 某个插件函数内部报错,但没有任何提示,用户只看到一片空白
统计显示,AI API 的平均可用性在 99.5% 左右,看起来很高,但对于每天数万次调用的系统,每天仍有数十次~数百次的失败请求——这些失败如果没有兜底,直接影响用户体验。
读完本文,你将掌握:
- ✅ Semantic Kernel 的异常体系与分类处理策略
- ✅ 基于 Polly 的智能重试机制(含指数退避)
- ✅ 熔断器模式防止雪崩效应
- ✅ 优雅降级设计:AI 挂了,业务仍然运转
- ✅ 一套可直接复用的生产级 AI 服务包装器
1️⃣ 问题深度剖析:那些"吞掉"的异常
最常见的错误写法
csharp// ❌ 典型的"掩盖问题"写法——很多项目里真实存在
public async Task<string> AskAIAsync(string prompt)
{
try
{
var result = await _kernel.InvokePromptAsync(prompt);
return result.ToString();
}
catch (Exception ex)
{
return "服务暂时不可用"; // 问题被掩盖,运维完全不知道发生了什么
}
}
这段代码的问题不是"有没有 catch",而是把所有异常一视同仁地吞掉了。网络超时、Rate Limit、Token 超限、参数错误——这些问题的处理策略完全不同,混在一起只会让排查困难度指数级上升。
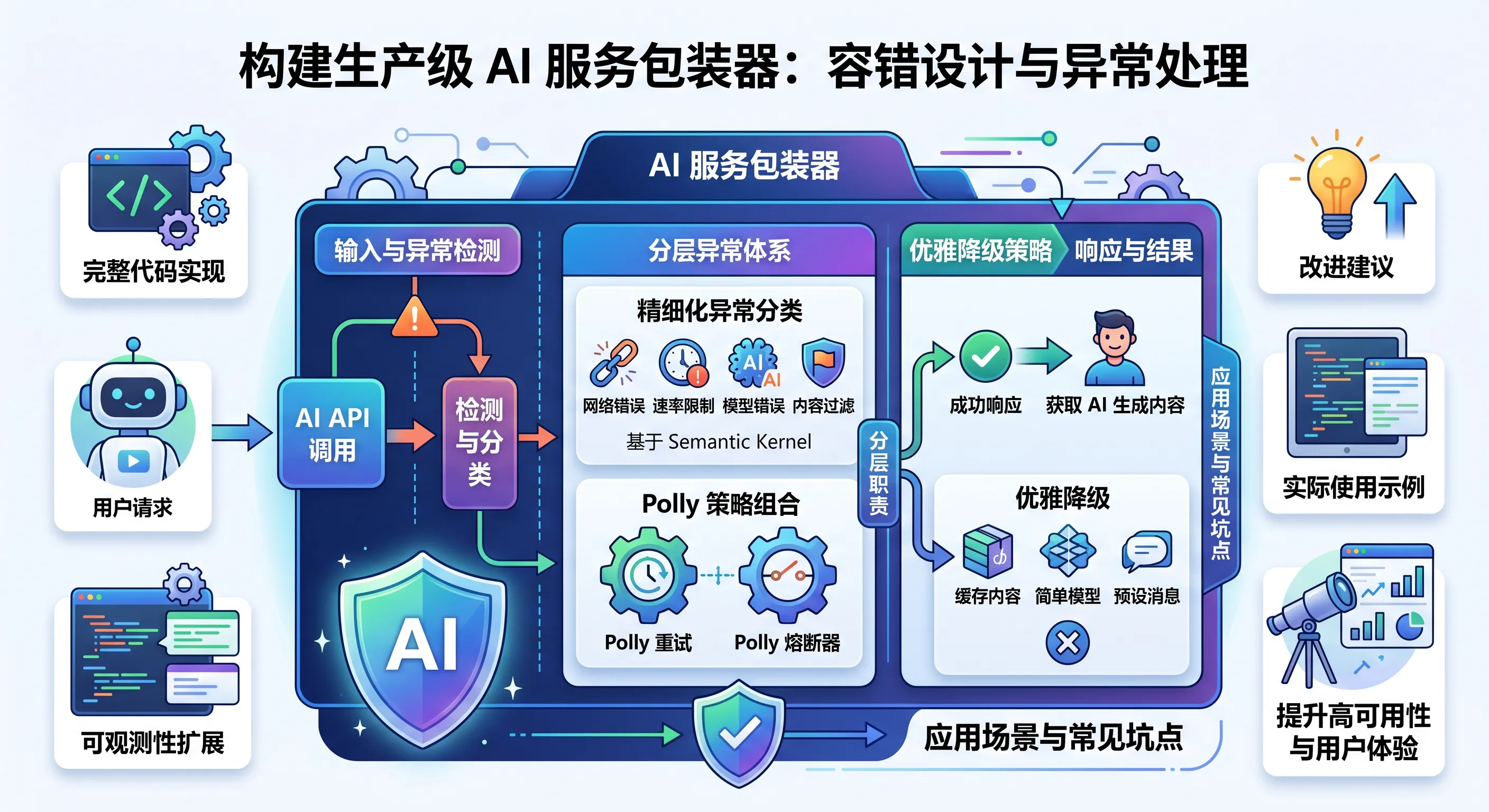
SK 异常体系分类
Semantic Kernel 的异常主要来自以下几层:
| 异常来源 | 典型异常类型 | 处理策略 |
|---|---|---|
| HTTP 网络层 | HttpRequestException | 重试 |
| API 限流 | 429 Too Many Requests | 延迟重试 |
| Token 超限 | 400 Bad Request | 截断历史,重试 |
| 函数调用失败 | KernelFunctionException | 记录 + 降级 |
| 插件内部错误 | Exception(包装后) | 降级处理 |
| 认证失败 | 401 Unauthorized | 直接告警,不重试 |
核心原则:可重试的错误要重试,不可重试的错误要快速失败,业务逻辑错误要优雅降级。
CustomTkinter软件授权系统实战:从零搭建简单防盗版机制
🔐 当你的软件被随意复制,你该怎么办?
做过桌面工具的开发者,大概都遇到过这种情况——花了几个月心血写出来的小工具,发出去没多久就被人打包转发,甚至有人直接拿去卖钱。气不气?当然气。但更现实的问题是:怎么防?
完全防住是不可能的,这一点咱们得想开。逆向工程、内存dump、代码混淆绕过……高手面前没有铜墙铁壁。但我们的目标不是对抗顶级黑客,而是提高普通用户随意传播的门槛,让"复制粘贴就能用"这条路走不通。
本文要做的事很具体:用 CustomTkinter 搭一套基于机器码绑定的本地授权系统,包含激活码生成、验证、界面集成的完整流程。代码全部可以直接跑,没有废话。
🧠 先想清楚:授权系统的本质是什么
很多人一上来就问"用什么加密算法",其实这个问题排在第二位。第一位的问题是:你的授权凭证跟什么绑定?
常见的绑定维度有三种:
账号绑定——需要联网验证,服务器说你有权限你才有。灵活,但需要维护后端,断网就凉。
设备绑定——把激活码跟某台机器的硬件特征挂钩,换台电脑就失效。离线可用,实现相对简单。
时间绑定——设置有效期,到期自动失效。通常和前两种结合使用。
咱们今天做的是设备绑定 + 本地验证的方案。核心逻辑是这样的:
用户机器 → 采集硬件特征 → 生成机器码 开发者拿到机器码 → 用密钥生成激活码 用户输入激活码 → 本地验证 → 解锁功能
没有服务器,没有联网请求,所有验证在本地完成。简单、稳定,适合个人开发者和小团队。
🛠️ 环境准备
依赖不多,几行装完:
bashpip install customtkinter pip install cryptography
cryptography 库负责加解密,customtkinter 负责界面。Python版本建议 3.9 及以上。
项目结构规划如下:
license_demo/ ├── main.py # 主程序入口 ├── license_core.py # 授权核心逻辑 ├── ui_activate.py # 激活界面 └── keygen.py # 开发者用的激活码生成工具