在Python GUI开发中,很多初学者都会遇到这样的困扰:界面元素摆放混乱、布局不够美观、复杂界面难以维护。这些问题的根源往往在于对Frame控件的理解不够深入。Frame作为tkinter中最基础也是最重要的布局控件,掌握它就像掌握了建筑的框架结构一样关键。
本文将从实战角度出发,带你深入理解Frame控件的核心原理和高级应用技巧。无论你是刚接触Python GUI开发的新手,还是希望提升界面设计水平的进阶开发者,都能从中获得实用的解决方案。让我们一起探索如何用Frame控件构建出专业级的GUI界面!
🔍 问题分析:为什么Frame控件如此重要?
界面布局的三大痛点
在Windows桌面应用开发中,我们经常遇到以下问题:
- 布局混乱:控件直接放在主窗口上,随着功能增加变得难以管理
- 响应式困难:窗口大小改变时,控件位置和大小无法合理调整
- 代码维护性差:复杂界面的代码冗长,后期修改困难重重
这些问题的核心在于缺乏结构化的布局思维。Frame控件正是解决这些问题的关键所在。
Frame控件的核心作用
Frame本质上是一个容器控件,它的主要作用包括:
- 逻辑分组:将相关的控件组织在一起
- 布局管理:提供独立的布局空间
- 样式控制:统一管理子控件的外观
- 事件处理:简化复杂界面的事件管理
💡 解决方案:Frame布局的三种核心策略
🎯 策略一:分层布局法
将界面按功能模块进行分层,每一层使用独立的Frame管理:
Pythonimport tkinter as tk
from tkinter import ttk
class LayeredFrame:
def __init__(self):
self.root = tk.Tk()
self.root.title("分层布局示例")
self.root.geometry("800x600")
# 创建主要布局框架
self.create_main_frames()
self.create_widgets()
def create_main_frames(self):
"""创建主要的布局框架"""
# 顶部工具栏框架
self.top_frame = tk.Frame(self.root, bg="#2E86C1", height=80)
self.top_frame.pack(fill="x", padx=5, pady=5)
self.top_frame.pack_propagate(False) # 固定高度
# 中间内容框架
self.middle_frame = tk.Frame(self.root, bg="#F8F9FA")
self.middle_frame.pack(fill="both", expand=True, padx=5)
# 底部状态栏框架
self.bottom_frame = tk.Frame(self.root, bg="#343A40", height=30)
self.bottom_frame.pack(fill="x", padx=5, pady=5)
self.bottom_frame.pack_propagate(False)
def create_widgets(self):
"""在各个框架中创建控件"""
# 顶部工具栏
tk.Label(self.top_frame, text="应用工具栏",
fg="white", bg="#2E86C1",
font=("微软雅黑", 16)).pack(pady=20)
# 中间内容区域
tk.Label(self.middle_frame, text="主要内容区域",
bg="#F8F9FA",
font=("微软雅黑", 14)).pack(expand=True)
# 底部状态栏
tk.Label(self.bottom_frame, text="就绪",
fg="white", bg="#343A40",
font=("微软雅黑", 10)).pack(side="left", padx=10)
if __name__ == "__main__":
app = LayeredFrame()
app.root.mainloop()
在Python桌面应用开发中,处理多行文本输入和显示是一个常见需求。无论是开发日志查看器、代码编辑器,还是聊天应用,我们都需要一个功能强大的多行文本组件。tkinter的Text控件正是为此而生,它不仅支持多行文本编辑,还提供了丰富的格式化功能和交互特性。
本文将从零开始,带你深入掌握Text控件的使用方法。我们将从基础语法讲起,逐步探索高级功能,最后通过实战项目帮你构建一个功能完整的文本编辑器。无论你是Python初学者还是想要提升GUI开发技能的程序员,这篇文章都将为你提供实用的解决方案。
🎯 Text控件基础入门
什么是Text控件
Text控件是tkinter中最强大的文本处理组件,支持:
- 多行文本编辑
- 富文本格式
- 文本搜索和替换
- 插入图片和窗口组件
- 撤销和重做操作
基础语法结构
Pythonimport tkinter as tk
from tkinter import ttk
# 创建主窗口
root = tk.Tk()
root.title("Text控件基础示例")
root.geometry("600x400")
# 创建Text控件
text_widget = tk.Text(
root,
width=50, # 宽度(字符数)
height=20, # 高度(行数)
wrap=tk.WORD, # 自动换行模式
font=("微软雅黑", 12)
)
text_widget.pack(padx=10, pady=10, fill=tk.BOTH, expand=True)
root.mainloop()
🔧 Text控件核心参数详解
常用配置参数
| 参数 | 说明 | 常用值 |
|---|---|---|
| width | 宽度(字符数) | 整数值 |
| height | 高度(行数) | 整数值 |
| wrap | 换行模式 | NONE, CHAR, WORD |
| state | 控件状态 | NORMAL, DISABLED |
| bg | 背景色 | 颜色值或颜色名 |
| fg | 前景色(文字颜色) | 颜色值或颜色名 |
| font | 字体 | (字体名, 大小, 样式) |
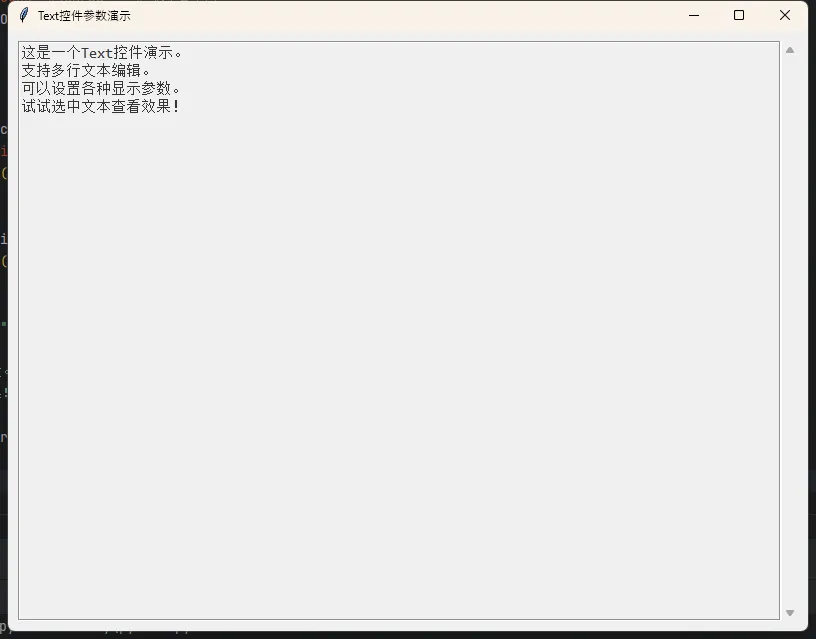
Pythonimport tkinter as tk
root = tk.Tk()
root.title("Text控件参数演示")
root.geometry("800x600")
# 创建带滚动条的Text控件
frame = tk.Frame(root)
frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
text_widget = tk.Text(
frame,
wrap=tk.WORD, # 按单词换行
bg="#f0f0f0", # 浅灰背景
fg="#333333", # 深灰文字
font=("Consolas", 11), # 等宽字体
insertbackground="red", # 光标颜色
selectbackground="#4CAF50", # 选中背景色
relief=tk.GROOVE, # 边框样式
bd=2 # 边框宽度
)
# 添加滚动条
scrollbar = tk.Scrollbar(frame)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
text_widget.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
# 绑定滚动条
text_widget.config(yscrollcommand=scrollbar.set)
scrollbar.config(command=text_widget.yview)
# 插入初始内容
initial_text = """这是一个Text控件演示。
支持多行文本编辑。
可以设置各种显示参数。
试试选中文本查看效果!"""
text_widget.insert(tk.END, initial_text)
root.mainloop()
在Windows桌面应用开发中,用户输入是不可或缺的交互环节。无论是登录界面的用户名密码输入,还是数据录入系统的表单填写,Entry输入框控件都扮演着关键角色。很多Python开发者在使用tkinter构建GUI应用时,对Entry控件的理解往往停留在表面,导致开发的应用在用户体验和功能完善度上存在明显短板。
本文将深入解析Entry输入框控件的核心特性和实战应用,帮助你彻底掌握这个看似简单却功能强大的控件。我们将从基础语法开始,逐步深入到高级应用技巧,确保你能在实际项目中灵活运用。
🔍 Entry控件核心特性分析
📌 什么是Entry控件
Entry是tkinter中专门用于单行文本输入的控件,它允许用户输入和编辑文本内容。与Text控件的多行输入不同,Entry专注于单行输入场景,在表单设计、参数配置、搜索框等应用中发挥重要作用。
🎨 Entry控件的关键特性
输入限制与验证:Entry控件支持输入长度限制、字符类型验证等功能,这对于数据规范性至关重要。
样式定制:通过丰富的配置选项,可以实现不同的视觉效果,包括边框样式、背景颜色、字体设置等。
事件响应:Entry控件能够响应多种用户操作事件,如键盘输入、鼠标点击、焦点变化等。
💡 Entry控件基础语法与配置
🚀 创建Entry控件的基本语法
Pythonimport tkinter as tk
# 创建主窗口
root = tk.Tk()
root.title("Entry控件基础示例")
root.geometry("400x300")
# 创建Entry控件的基本方法
entry = tk.Entry(root)
entry.pack(pady=20)
root.mainloop()
在Python桌面开发中,按钮控件是用户交互的核心组件。无论你是开发数据处理工具、设备控制软件还是管理系统,Button控件都是必不可少的界面元素。本文将从零开始,深入解析Tkinter Button控件的使用方法,帮助你快速掌握Python GUI开发的核心技能。通过实际案例和最佳实践,让你的Python开发技能更上一层楼,为后续的上位机开发打下坚实基础。
🎯 Button控件核心概念
什么是Button控件
Button控件是Tkinter中最基础的交互组件,它允许用户通过点击触发特定的功能。在实际的Python开发项目中,按钮承担着连接用户操作和程序逻辑的重要桥梁作用。
Button控件的本质
从技术角度看,Button是一个可点击的矩形区域,包含文本、图片或两者的组合。当用户点击时,会触发绑定的回调函数,执行相应的业务逻辑。
🔧 基础语法与参数详解
创建Button的标准语法
Pythonimport tkinter as tk
button = tk.Button(parent, option=value, ...)
核心参数全览
Pythonimport tkinter as tk
root = tk.Tk()
root.title("Button参数演示")
root.geometry("400x300")
# 基础按钮
basic_button = tk.Button(
root,
text="点击我", # 按钮文本
command=lambda: print("按钮被点击!"), # 点击回调函数
width=15, # 宽度(字符数)
height=2, # 高度(文本行数)
bg="lightblue", # 背景色
fg="black", # 前景色(文字颜色)
font=("微软雅黑", 12), # 字体设置
relief="raised", # 边框样式
bd=3, # 边框宽度
state="normal" # 状态:normal, disabled, active
)
basic_button.pack(pady=20)
root.mainloop()
如果你刚开始学习Python GUI开发,是否遇到过这样的困惑:想要在窗口中显示文本信息,却不知道如何下手?或者看到别人制作的精美界面,不知道那些文字、图片是怎么添加上去的?
Label标签控件是Tkinter中最基础也是最常用的组件之一,它就像是GUI界面的"文字工具",负责在窗口中显示静态文本、图像或者两者的组合。掌握Label控件,是每个Python开发者踏入GUI编程的第一步。
本文将从零开始,详细讲解Label控件的使用方法,通过丰富的代码实例,让你快速掌握这个GUI开发的基础技能。无论你是Python初学者,还是想要转型做上位机开发的工程师,这篇文章都将为你打下坚实的GUI编程基础。
🔍 问题分析
Label控件的核心作用
在实际的Python开发项目中,Label控件主要解决以下几个问题:
1. 信息展示需求
- 显示程序状态信息
- 展示用户输入的结果
- 提供操作提示和说明文字
2. 界面美化需求
- 添加logo图片
- 设置背景图像
- 创建视觉层次感
3. 用户交互指导
- 标识输入框的用途
- 提供操作步骤说明
- 显示实时数据更新
💡 解决方案
🏗️ Label控件的基本语法结构
Label控件的创建遵循Tkinter的标准模式:
Pythonlabel = tkinter.Label(parent, options)
其中:
- parent:父容器(通常是根窗口或Frame)
- options:配置参数,控制Label的外观和行为
🎨 核心配置参数详解
| 参数名 | 作用 | 常用值示例 |
|---|---|---|
| text | 显示的文本内容 | "Hello World" |
| font | 字体设置 | ("Arial", 12, "bold") |
| fg/foreground | 文字颜色 | "red", "#FF0000" |
| bg/background | 背景颜色 | "white", "#FFFFFF" |
| width/height | 控件尺寸 | width=20, height=5 |
| anchor | 文本对齐方式 | "w", "center", "e" |
| image | 显示图像 | PhotoImage对象 |
🚀 代码实战
📝 基础示例:创建第一个Label
让我们从最简单的例子开始:
Pythonimport tkinter as tk
# 创建主窗口
root = tk.Tk()
root.title("Label基础示例")
root.geometry("400x300")
# 创建基础Label
label1 = tk.Label(root, text="欢迎学习Python Tkinter!")
label1.pack(pady=20)
# 启动事件循环
root.mainloop()