你是否经常为Matplotlib绘图中的**Figure和Axes**概念感到困惑?
在Python数据可视化开发中,特别是Windows环境下的上位机开发,很多开发者在使用Matplotlib时都会遇到这样的问题:代码能跑,图能出来,但总感觉对底层逻辑一知半解。当需要创建复杂的多子图布局或精确控制图形属性时,就显得束手束脚。
本文将从实战角度出发,用通俗易懂的方式帮你彻底理解Matplotlib的Figure和Axes概念,掌握创建图形的不同方式,并学会灵活运用plt.subplots()函数。无论你是数据分析新手还是有一定基础的开发者,这篇文章都能让你的Python可视化技能更上一层楼。
🎨 Figure与Axes:画布与画板的关系
🤔 概念解析:一个形象的比喻
想象你在画画:
- Figure 就像是你的画布(整张纸)
- Axes 就像是画板(纸上的绘图区域)
在一张画布上,你可以放置多个画板,每个画板都可以独立绘制不同的内容。
Pythonimport matplotlib.pyplot as plt
import numpy as np
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans'] # 设置字体
plt.rcParams['axes.unicode_minus'] = False
# 使用标准后端而不是PyCharm的后端
import matplotlib
matplotlib.use('TkAgg') # 或者 'Qt5Agg'
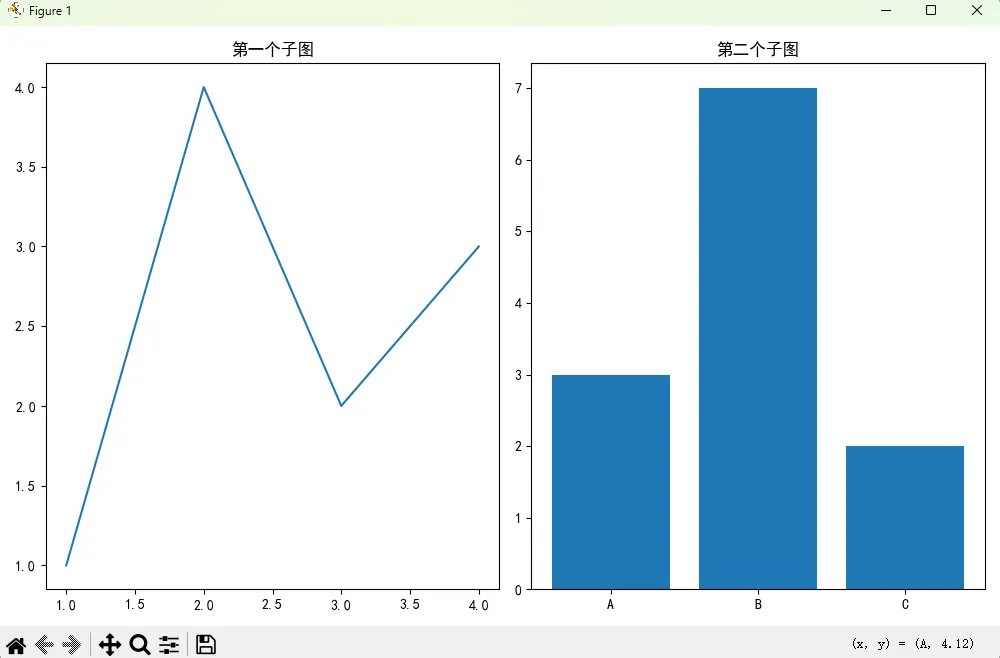
# 创建一个Figure(画布)
fig = plt.figure(figsize=(10, 6))
# 在画布上添加第一个Axes(画板)
ax1 = fig.add_subplot(1, 2, 1) # 1行2列的第1个位置
ax1.plot([1, 2, 3, 4], [1, 4, 2, 3])
ax1.set_title('第一个子图')
# 在画布上添加第二个Axes(画板)
ax2 = fig.add_subplot(1, 2, 2) # 1行2列的第2个位置
ax2.bar(['A', 'B', 'C'], [3, 7, 2])
ax2.set_title('第二个子图')
plt.tight_layout() # 自动调整子图间距
plt.show()
在 PyCharm 中,进入 File → Settings → Tools → Python Scientific → Show plots in tool window,取消勾选这个选项,这样图表会在独立窗口中显示,避免使用 PyCharm 的内置后端
💡 核心区别总结
| 概念 | 作用 | 特点 | 常用方法 |
|---|---|---|---|
| Figure | 整个图形窗口/画布 | 包含所有图形元素 | set_size_inches(), savefig() |
| Axes | 具体的绘图区域 | 包含数据、坐标轴、标签 | plot(), bar(), set_title() |
在Python桌面应用开发中,很多初学者在面对Tkinter GUI编程时常常感到无从下手。特别是当需要创建一个包含文本显示、用户输入和按钮交互的完整界面时,往往不知道如何让Label、Button、Entry这三个基础控件协同工作。
本文将从实战角度出发,通过一个完整的用户登录界面项目,带你掌握这三个核心控件的组合使用技巧。你将学会如何构建美观实用的GUI界面,掌握控件间的数据传递和事件处理,最终能够独立开发具有交互功能的Python桌面应用程序。
🔍 问题分析:为什么要掌握这三个控件?
在任何GUI应用中,Label(标签)、Button(按钮)、**Entry(输入框)**构成了用户界面的黄金三角:
- Label:负责信息展示和界面提示
- Entry:处理用户输入数据
- Button:触发程序逻辑执行
这三个控件的配合使用几乎涵盖了90%的桌面应用交互场景,掌握它们的组合技巧是Python GUI开发的基石。
💡 解决方案:构建完整的交互系统
🎨 设计思路
我们将创建一个用户登录系统,包含以下功能:
- 用户名和密码输入
- 登录状态显示
- 清空和登录按钮
- 输入验证和反馈机制
📊 控件职责分工
| 控件类型 | 具体用途 | 交互方式 |
|---|---|---|
| Label | 标题、字段说明、状态提示 | 信息展示 |
| Entry | 用户名、密码输入 | 数据收集 |
| Button | 登录、清空、退出操作 | 事件触发 |
在Python GUI开发中,Tkinter作为标准库深受Windows开发者青睐。然而,很多初学者在使用Tkinter时,往往只知道pack()和grid()布局管理器,却忽略了功能强大的place布局管理器。
place布局管理器提供了像素级精确定位的能力,让你可以像使用Photoshop一样自由控制界面元素的位置和大小。这在开发需要精确布局的上位机界面、数据可视化应用或自定义控件时显得尤为重要。
本文将从实战角度深入解析place布局管理器的使用技巧,帮助你掌握这个被低估的布局利器。
🔍 问题分析:为什么需要place布局管理器
传统布局方式的局限性
在实际Windows应用开发中,pack()和grid()布局管理器虽然简单易用,但存在明显局限:
pack()布局的问题:
- 只能沿着一个方向填充(上下或左右)
- 难以实现复杂的层叠效果
- 无法精确控制元素间距
grid()布局的问题:
- 受表格结构限制,难以实现不规则布局
- 跨行跨列操作复杂
- 无法实现浮动效果
place布局的优势
精确定位:支持绝对位置和相对位置定位
灵活布局:不受网格限制,可实现任意布局
层叠控制:支持元素重叠和层级管理
响应式设计:支持相对大小和位置调整
💡 解决方案:place布局核心参数详解
📍 位置控制参数
place布局提供了多种位置控制方式:
Python# 绝对位置定位(像素为单位)
widget.place(x=100, y=50)
# 相对位置定位(相对于父容器的比例)
widget.place(relx=0.5, rely=0.3)
# 混合定位(相对位置 + 偏移量)
widget.place(relx=0.5, rely=0.5, x=10, y=-20)
参数说明:
- x, y:绝对像素位置
- relx, rely:相对位置(0.0-1.0)
- 可以同时使用,实现更灵活的定位
📏 尺寸控制参数
Python# 绝对尺寸(像素)
widget.place(width=200, height=100)
# 相对尺寸(相对于父容器)
widget.place(relwidth=0.8, relheight=0.6)
# 组合使用
widget.place(relwidth=0.5, height=100)
在Python GUI开发中,界面布局往往是让初学者头疼的问题。明明代码写得没错,但控件要么挤在一起,要么分布混乱,完全达不到预期效果。特别是当我们需要创建复杂的表格式布局时,传统的pack布局就显得力不从心了。
今天这篇文章,我将带你深入了解Tkinter中最强大、最灵活的布局管理器——Grid布局。从基础概念到高级技巧,从简单示例到复杂应用,让你彻底掌握Grid布局的精髓。无论你是Python初学者,还是想要提升GUI开发技能的程序员,这篇文章都将为你的编程之路添砖加瓦。
🔍 问题分析:为什么需要Grid布局?
Pack布局的局限性
在学习Grid之前,我们先来看看为什么Pack布局在复杂界面中会显得不足:
Pythonimport tkinter as tk
root = tk.Tk()
root.title("Pack布局的局限性")
# 使用pack布局创建登录界面
tk.Label(root, text="用户名:").pack()
tk.Entry(root).pack()
tk.Label(root, text="密码:").pack()
tk.Entry(root, show="*").pack()
tk.Button(root, text="登录").pack()
root.mainloop()
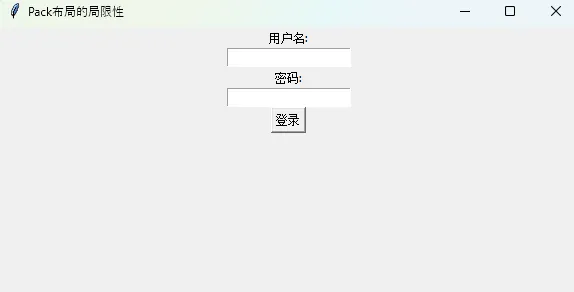
这样的布局虽然简单,但控件只能垂直或水平排列,无法实现复杂的表格式布局。
Grid布局的优势
Grid布局将容器划分为行和列的网格,每个控件可以精确地放置在指定的网格位置,具有以下优势:
- 🎯 精确定位:可以将控件放置在任意行列位置
- 🔄 灵活扩展:控件可以跨越多行或多列
- ⚖️ 智能调整:支持权重分配和自适应调整
- 🎨 对齐控制:提供丰富的对齐选项
在Python桌面应用开发中,Tkinter作为Python标准库的GUI工具包,是许多开发者的首选。然而,很多初学者在布局管理上经常遇到困惑:为什么控件显示不出来?为什么布局总是不按预期排列?为什么界面看起来这么不专业?
本文将深入解析Tkinter中最基础也是最重要的pack布局管理器,通过详实的代码示例和实战技巧,帮你彻底掌握pack布局的精髓,让你的GUI界面从"能用"升级到"好用",从"业余"提升到"专业"。
🔍 pack布局管理器基础认知
什么是pack布局管理器?
pack布局管理器是Tkinter中三大布局管理器之一(另外两个是grid和place),它采用块状布局的方式,将控件按照指定方向依次排列,就像搭积木一样。
pack的核心思想是:
- 方向性排列:控件沿着指定方向(上下左右)依次放置
- 空间填充:可以让控件填充剩余空间
- 简单高效:代码量少,适合简单布局
🚀 pack基础语法深度解析
核心参数详解
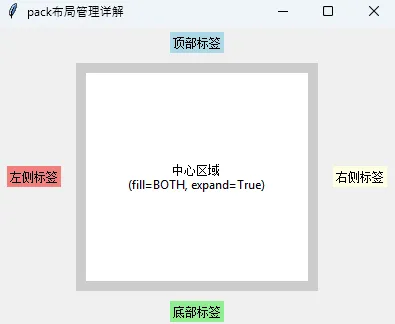
Pythonimport tkinter as tk
root = tk.Tk()
root.title("pack布局管理详解")
root.geometry("400x300")
# 创建实际的widget并使用pack布局
# 示例1:基本使用
label1 = tk.Label(root, text="顶部标签", bg="lightblue")
label1.pack(side=tk.TOP, pady=5)
label2 = tk.Label(root, text="底部标签", bg="lightgreen")
label2.pack(side=tk.BOTTOM, pady=5)
label3 = tk.Label(root, text="左侧标签", bg="lightcoral")
label3.pack(side=tk.LEFT, padx=10)
label4 = tk.Label(root, text="右侧标签", bg="lightyellow")
label4.pack(side=tk.RIGHT, padx=10)
# 示例2:fill和expand的使用
frame = tk.Frame(root, bg="gray80")
frame.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
center_label = tk.Label(frame, text="中心区域\n(fill=BOTH, expand=True)",
bg="white", justify=tk.CENTER)
center_label.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
root.mainloop()