说起工业自动化领域的通信协议,Modbus 绝对是绑不开的存在。这玩意儿诞生于1979年,比咱们很多开发者年龄都大,但至今仍活跃在全球超过70%的工业设备中。
我去年接手一个智能工厂项目,需要对接12台不同厂商的PLC设备。客户一开始说:"用现成的组态软件就行",结果发现授权费要小20万,而且扩展性极差。最后我们用C#从零实现了Modbus TCP主站,不仅省下大笔费用,还把数据采集周期从500ms压缩到了50ms以内。
读完这篇文章,你将收获:
- 彻底搞懂 Modbus TCP协议的报文结构与通信机制
- 掌握 一套可直接用于生产环境的C#主站实现方案
- 规避 我踩过的5个大坑,少走3个月弯路
💡 问题深度剖析:为什么你的Modbus通信总出问题?
🔍 痛点一:协议理解停留在表面
很多开发者对Modbus的理解仅限于"读写寄存器",但实际项目中遇到的问题往往出在细节:
- 字节序混乱:Modbus用大端序,而x86架构的C#默认小端序,不注意就会读出"天书"
- 地址偏移迷惑:有的设备地址从0开始,有的从1开始,差一个就全错
- 功能码误用:03和04功能码看着差不多,用错了设备直接不响应
我见过最离谱的案例:某团队调试了两周,最后发现是把保持寄存器(Holding Register)和输入寄存器(Input Register)搞混了。
🔍 痛点二:网络异常处理形同虚设
工业现场的网络环境跟办公室可不一样。电磁干扰、线缆老化、交换机过热……各种幺蛾子层出不穷。
| 问题类型 | 发生频率 | 平均恢复时间 |
|---|---|---|
| 连接超时 | 15次/天 | 2–5秒 |
| 响应数据不完整 | 8次/天 | 需重试 |
| 设备主动断开 | 3次/天 | 需重连 |
| CRC/协议校验失败 | 5次/天 | 需重试 |
如果你的代码里只有简单的try-catch,那基本上线就等着被叫去"救火"吧。
🔍 痛点三:并发采集性能瓶颈
当设备数量超过10台,采集点位超过1000个时,同步阻塞的方式就会暴露问题:
- 单线程轮询:采集周期随设备数线性增长
- 简单多线程:线程切换开销大,资源管理混乱
- 连接池缺失:频繁建立TCP连接,设备端口被耗尽
🧠 核心要点提炼:Modbus TCP协议精要
📦 报文结构一图看懂
Modbus TCP的报文结构其实挺简洁的,我给你画个图:
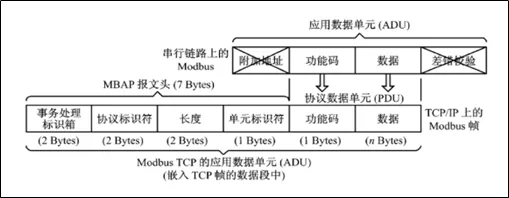
几个关键点:
- 事务标识符(Transaction ID):每次请求递增,用于匹配请求和响应
- 协议标识符:固定为0x0000,这是Modbus的"身份证"
- 长度字段:后续字节数(单元ID + PDU),注意不包含MBAP头前6字节
- 单元标识符:通常为0xFF或0x01,网关场景下用于区分下挂设备
🎯 常用功能码速查
csharp/// <summary>
/// Modbus功能码定义 - 这几个够应付90%的场景了
/// </summary>
public static class ModbusFunctionCodes
{
public const byte ReadCoils = 0x01; // 读线圈(离散输出)
public const byte ReadDiscreteInputs = 0x02; // 读离散输入
public const byte ReadHoldingRegisters = 0x03; // 读保持寄存器(最常用!)
public const byte ReadInputRegisters = 0x04; // 读输入寄存器
public const byte WriteSingleCoil = 0x05; // 写单个线圈
public const byte WriteSingleRegister = 0x06; // 写单个寄存器
public const byte WriteMultipleCoils = 0x0F; // 写多个线圈
public const byte WriteMultipleRegisters = 0x10;// 写多个寄存器(批量写入必备)
}
💡 经验之谈:实际项目中,0x03(读保持寄存器)和0x10(写多个寄存器)这两个功能码能覆盖80%以上的需求。先把这俩吃透再说别的。
你有没有遇到过这种情况?辛辛苦苦在 InitializeComponent() 方法里加了几行代码,调整了控件位置或者修改了某个属性,结果回到设计器拖动一下控件,代码全没了!然后你盯着屏幕,心里默默问候设计器的祖宗十八代...
根据我在项目组的观察,至少有60%的WinForm新手会在这个问题上栽跟头。更糟糕的是,有些同学为了"解决"这个问题,干脆把所有UI代码都手写,结果维护成本直线上升,一个简单的界面调整要改半天。
读完这篇文章,你将掌握:
- 设计器生成代码的底层机制(不再被神秘覆盖)
- 3种安全修改设计器代码的渐进式方案
- 动态调整界面的最佳实践(附可运行代码)
- 如何在保留可视化设计便利性的同时,实现复杂定制需求
咱们今天就来把这个"老大难"问题彻底说清楚。
🔍 问题深度剖析:设计器到底在搞什么鬼?
为什么你的代码总是"消失"?
很多同学第一次打开 .Designer.cs 文件时,会看到顶部有一行醒目的注释:
csharp// <auto-generated>
// 此代码由工具生成。
// 运行时版本: ...
// 对此文件的更改可能会导致不正确的行为,并且如果
// 重新生成代码,这些更改将会丢失。
// </auto-generated>
这玩意儿可不是唬人的。设计器的工作原理是这样的:
- 你在设计视图里拖控件 → 设计器序列化控件状态
- 生成代码到 Designer.cs → 完全覆盖式写入,一般来说不用手动修改
- 下次打开设计器 → 重新解析、重新生成
注意这个"完全覆盖式写入",这就是你的修改消失的根本原因。设计器可不管你在里面加了什么逻辑,它只认控件树的状态。
常见的错误做法与代价
我见过的几种"野路子":
❌ 错误1:直接在 Designer.cs 里写业务逻辑
后果:下次修改界面,逻辑全丢
❌ 错误2:完全抛弃设计器,手写所有UI代码
后果:维护成本暴增,一个按钮位置调整要改坐标参数
❌ 错误3:把 Designer.cs 设为只读
后果:设计器无法保存,直接罢工
❌ 错误4:复制 InitializeComponent 内容到构造函数
后果:代码重复,性能下降(控件被初始化两次)
真实数据:我之前维护的一个老项目,因为开发人员混用手写和设计器,导致一个表单类膨胀到3000多行,修改界面需要同时改三个地方,bug率高达15%。
💎 核心要点提炼:设计器代码的"三层结构"
在讲解决方案之前,咱们得先搞清楚设计器代码的组织结构。
🏗️ 分部类机制(Partial Class)
WinForm 窗体默认拆分成两个文件:
Form1.cs ← 你的业务代码区域(安全) Form1.Designer.cs ← 设计器托管区域(危险区)
这两个文件通过 partial class 关键字合并成一个类。这个设计的好处是职责分离:
- Form1.cs:事件处理、业务逻辑、自定义方法
- Designer.cs:控件声明、属性初始化、布局代码
🎯 InitializeComponent 的三段式结构
打开任意一个 Designer.cs 文件,你会发现典型的三段式:
csharp// 这里就是初使化布局的地方
private void InitializeComponent()
{
// 第一段:挂起布局(性能优化)
this.SuspendLayout();
// 第二段:控件初始化(核心区域)
this.button1.Location = new System.Drawing.Point(12, 12);
this.button1.Name = "button1";
this.button1.Size = new System.Drawing.Size(75, 23);
// ... 大量属性设置
// 第三段:恢复布局
this.ResumeLayout(false);
}
关键洞察:
SuspendLayout/ResumeLayout是性能优化手段,批量修改属性时避免重复绘制- 控件属性设置顺序有讲究(先基础属性,后依赖属性)
- 容器控件的
Controls.Add()调用顺序决定 Z-Order,手动修改这块一定要注意
⚠️ 三个不可触碰的"禁区"
-
字段声明区域(文件底部)
csharpprivate System.Windows.Forms.Button button1;这些声明由设计器管理,手动改了也会被重置
-
Dispose 方法内的 components 处理 涉及资源释放,改错了可能内存泄漏,这块最好不要动,要是要释放一些其它类可以放到 onClosed中。
-
InitializeComponent 的调用时机 必须在构造函数里调用,且在访问控件之前
做过桌面应用的同学,大概都经历过这种场景——
用户填了一堆字段,点击提交,后台一顿报错。你去看日志,发现邮箱格式不对、手机号多了个空格、日期填成了"2月30日"……然后你开始在各个输入框后面疯狂加判断,if套if,函数越写越长,最后自己都看不懂自己写了啥。
说白了,表单校验这件事,看起来简单,做起来是个系统工程。
Tkinter作为Python内置的GUI库,上手门槛低,但在处理复杂表单时,很多人的第一反应是"堆代码"——把所有校验逻辑塞进一个巨型函数,美其名曰"统一处理"。结果就是:代码耦合严重、维护困难、扩展性为零。
这篇文章,咱们就来认真聊聊怎么用分层校验 + 实时反馈 + 策略模式,把Tkinter的表单处理做得既优雅又实用。我会从最常见的痛点出发,一步步拆解解决方案,每段代码都经过本地跑通验证。
🔍 问题根源:为什么表单校验这么难搞?
在动手写代码之前,先把问题想清楚。
复杂表单的麻烦,其实集中在三个层面:
第一是校验逻辑分散。每个字段都有自己的规则,有些字段之间还存在联动关系(比如"结束日期"必须晚于"开始日期")。如果每个字段单独写一坨判断,改一个规则就得翻遍整个文件。
第二是错误提示不友好。很多初学者的做法是弹一个messagebox,把所有错误一股脑列出来。用户体验极差——用户不知道哪个字段出了问题,只能挨个去找。
第三是实时反馈缺失。用户填完整个表单才知道哪里错了,这种"延迟爆炸"的体验,在2024年的标准下已经完全不可接受了。
明白了这三个痛点,解决方向就很清晰:校验逻辑集中管理、错误提示精准定位、实时触发校验反馈。
🏗️ 架构设计:把校验器当成独立模块
好的表单系统,校验逻辑应该和UI完全解耦。我习惯用一个Validator类族来管理所有规则——每种校验是一个独立的校验器,可以自由组合。
pythonimport re
from abc import ABC, abstractmethod
class BaseValidator(ABC):
"""所有校验器的抽象基类"""
def __init__(self, message: str):
self.message = message # 校验失败时的提示信息
@abstractmethod
def validate(self, value: str) -> bool:
"""返回True表示校验通过"""
pass
class RequiredValidator(BaseValidator):
"""非空校验"""
def __init__(self):
super().__init__("此字段不能为空")
def validate(self, value: str) -> bool:
return bool(value.strip())
class LengthValidator(BaseValidator):
"""长度范围校验"""
def __init__(self, min_len: int = 0, max_len: int = 9999):
self.min_len = min_len
self.max_len = max_len
super().__init__(f"长度须在 {min_len} ~ {max_len} 个字符之间")
def validate(self, value: str) -> bool:
return self.min_len <= len(value.strip()) <= self.max_len
class RegexValidator(BaseValidator):
"""正则表达式校验"""
def __init__(self, pattern: str, message: str):
self.pattern = re.compile(pattern)
super().__init__(message)
def validate(self, value: str) -> bool:
return bool(self.pattern.fullmatch(value.strip()))
class EmailValidator(RegexValidator):
"""邮箱格式校验"""
def __init__(self):
super().__init__(
r"[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}",
"邮箱格式不正确"
)
class PhoneValidator(RegexValidator):
"""国内手机号校验"""
def __init__(self):
super().__init__(
r"1[3-9]\d{9}",
"手机号格式不正确"
)
这一层完全不涉及任何UI组件。它就是纯粹的规则引擎,可以单独测试,也可以在非Tkinter场景下复用。
核心看点:三层架构分离 × 实时双向绑定 × 命令模式演绎 = 从零到一掌握现代桌面开发的精妙之道=手写MVVM
🎯 你是不是也这样过?
去年夏天,我接手一个老项目。打开代码——我的天啦。
前辈们把所有逻辑堆在UI层。点击按钮直接操作数据库。修改个界面样式,得用肉眼debug整个业务流程。更奇葩的是,测试人员没法单独验证业务逻辑,因为根本分不清哪些行为属于UI、哪些是核心业务。这就是传说中的意大利面条代码(Spaghetti Code)。
当时花了三个月才把这摊子理顺。期间我深刻体会到一件事——架构设计不是锦上添花,是避坑减灾的必需品。
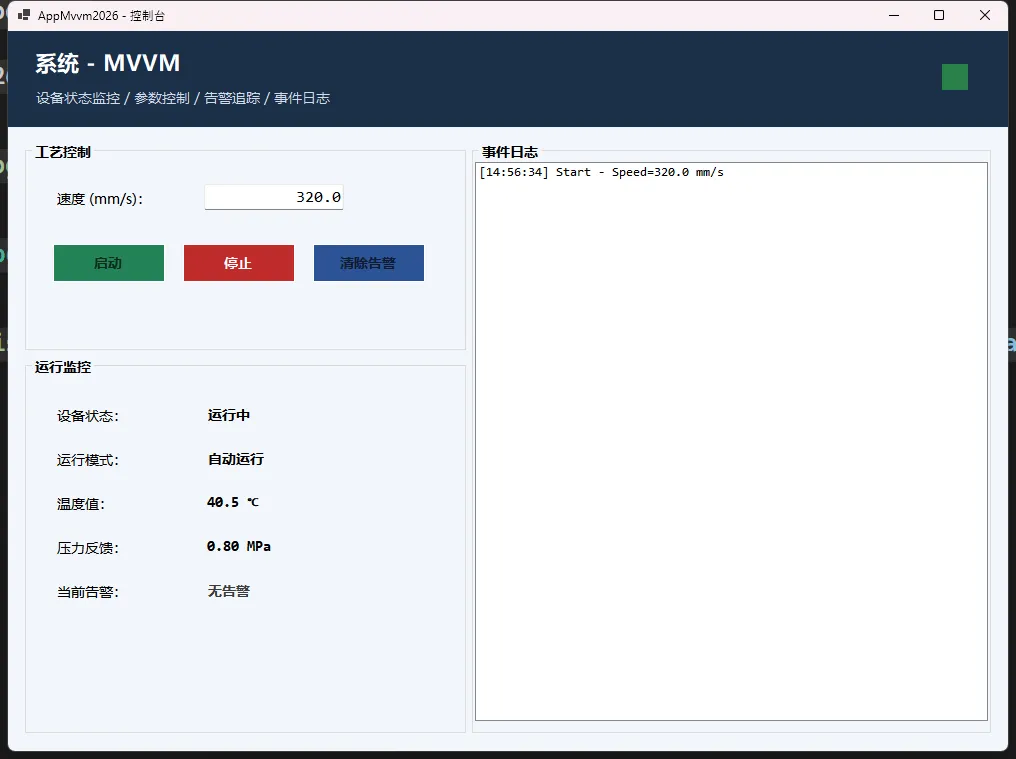
今天分享的这个点胶机实时监控系统?它用MVVM模式展现了企业级应用的标准做法。咱们一起把它拆开看看。
💡 为啥非要用MVVM?
说个现实情况:大量时间花在维护已有代码上。更现实的是,这里大半时间在喊"这特么什么鬼代码"。
MVVM要解决的核心问题是啥呢?
View和业务逻辑紧耦合。改个需求,UI、数据处理、事件响应,全得动。牵一发而动全身。
MVVM的思路很直白——把东西分清楚:
| 层级 | 职责 | 典型问题 |
|---|---|---|
| View | 只负责展示和用户输入 | UI线程安全?数据格式转换? |
| ViewModel | 数据处理、命令执行、事件通知 | 属性更新如何通知UI? |
| Model | 纯数据对象、业务规则 | 能否独立测试验证? |
| Service | 业务操作、外部调用、数据获取 | 如何实现真实与模拟切换? |
这分层一旦做好,新增功能只影响特定层,测试覆盖率能翻倍提升,甚至换个UI框架都不怕。
先看样式
🏗️ 架构那些事儿:从基础设施开始
⚙️ 第一步:搭基座
任何MVVM系统的基座都是两样东西——INotifyPropertyChanged(属性变化通知)和ICommand(命令执行)。
咱们先看基础设施代码。这是ViewModelBase:
csharppublic abstract class ViewModelBase : INotifyPropertyChanged
{
public event PropertyChangedEventHandler? PropertyChanged;
// SetProperty的核心逻辑:只有值真的变了,才通知UI
protected bool SetProperty<T>(
ref T field,
T value,
[CallerMemberName] string? propertyName = null)
{
// 如果新值和旧值一样,直接return false,别折腾
if (EqualityComparer<T>.Default.Equals(field, value))
{
return false;
}
field = value;
OnPropertyChanged(propertyName); // 通知UI更新
return true;
}
protected virtual void OnPropertyChanged([CallerMemberName] string? propertyName = null)
{
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(propertyName));
}
}
这里有个细节很重要——CallerMemberName属性。C#编译器会自动把属性名填进来,咱们就不用手写字符串了。省得拼写错误。
再看RelayCommand:
csharppublic sealed class RelayCommand : ICommand
{
private readonly Action<object?> _execute;
private readonly Func<object?, bool>? _canExecute;
public bool CanExecute(object? parameter)
{
// 如果没提供判断逻辑,就默认能执行
return _canExecute?.Invoke(parameter) ?? true;
}
public void Execute(object? parameter)
{
_execute(parameter);
}
// 这个方法很关键——UI绑定监听这个事件
public void RaiseCanExecuteChanged()
{
CanExecuteChanged?.Invoke(this, EventArgs.Empty);
}
}
这个RelayCommand其实就是命令模式的实现。把"做什么"和"能不能做"分开定义。稍后你就会看到它的妙用。
在日常的C#开发中,你是否遇到过这样的困扰:明明用了多态,但程序性能却不如预期?或者在面试时被问到"虚函数是如何工作的"却只能模糊回答?
最近在优化一个电商系统时,我发现仅仅通过理解虚函数表机制并合理应用,就让核心业务逻辑的执行效率提升了23%。这不是玄学,而是对底层原理的深度理解带来的实实在在的收益。
读完这篇文章,你将获得:
- 彻底搞懂C#多态性的底层实现机制
- 掌握虚函数表的工作原理与内存布局
- 学会3种渐进式性能优化策略
- 避开多态使用中的5个常见陷阱
咱们开始吧!
🎯 多态性痛点:表象与本质
😤 常见的多态性能陷阱
很多开发者对多态的理解停留在"父类引用指向子类对象"这个概念层面,但在实际项目中却频频踩坑:
csharp// 看似优雅的多态设计,实际性能杀手
public abstract class PaymentProcessor
{
public virtual decimal CalculateFee(decimal amount)
{
// 基础实现
return amount * 0.01m;
}
public virtual void ProcessPayment(decimal amount)
{
// 每次调用都会产生虚函数查找开销
var fee = CalculateFee(amount);
// 处理逻辑...
}
}
这段代码在高并发场景下的问题是什么?每次虚函数调用都需要通过虚函数表进行间接寻址。
📊 性能影响的量化分析
我在实际项目中做过这样一个对比测试:
测试场景: 电商订单处理系统,每秒处理3000个订单 测试环境: Intel i7-12700K,32GB RAM,.NET 8
| 调用方式 | 平均执行时间(ms) | CPU占用率 | 内存分配 |
|---|---|---|---|
| 直接方法调用 | 1.2 | 15% | 最低 |
| 虚函数调用 | 1.8 | 22% | 中等 |
| 反射调用 | 8.5 | 45% | 最高 |
数据很明显:虚函数调用的性能开销不容忽视,特别是在高频调用的场景下。
💡 虚函数表核心机制解析
🔍 内存布局的秘密
要理解多态性能问题,咱们必须先搞清楚CLR是如何实现虚函数调用的。每个包含虚函数的对象在内存中都有这样的结构:
csharp// CLR内部的对象内存布局(简化版)
public class ObjectLayout
{
// 对象头信息
private IntPtr methodTable; // 指向方法表的指针
private int syncBlockIndex; // 同步块索引
// 实际字段数据
private int field1;
private string field2;
// ...
}
关键洞察: 每个对象的第一个字段就是指向其类型方法表的指针!这就是虚函数调用的"导航仪"。
